Elasticsearch: Terminology and Architecture
Publish Date: 2022-09-15

How to Store data is what differentiates search engines databases from traditional databases, plus search engines store the index as well. if that so, then what makes the difference between indexing in databases like MongoDB or MySQL and search engines databases like Solr and Elasticsearch?
Well, search engines do a lot more: they provide capabilities in information retrieval that are not regularly available in other database classes. These databases use data structures and algorithms to provide scalable and efficient indexing and searching of documents, using terms and phrases in a language-aware context, and that is what makes them special.
In this article we will learn the main concept and terminology related to Elasticsearch, one of the most popular search engine databases, along with its architecture and how it fit for large scale data workloads.
Apache Lucene: backend heart of Elasticsearch
Apache Lucene is a most popular full-text search java-based library, that can be included in any application to deliver scalable and efficient index and search features, using techniques and algorithms in the field of information retrieval. its database structure is an index and is mostly called an inverted index, and this is a structure that points to terms/tokens in documents that contains the terms.
Lucene is not a database; it is a library that you can use to add full-text search functionality to applications. It is used in many search engine databases, the most popular are Solr and Elasticsearch.
We use these search engines when we build public and enterprise search applications, and it can be used as a backend to NLP (Natural Language Processing) based analytics, or ML (machine learning) based pipelines.
What is Elasticsearch
Elasticsearch is an open source horizontally scalable search engine that is built on top of Apache Lucene, it extends the Lucene full-text search functionalities, to provide a database solution for scalable indexing, searching, sorting, and analysis of data, whether it is structured, semi-structured or unstructured datasets.
It's built using java, and it uses RESTful API over HTTP to send and receive data in JSON format with clients. And beyond searching, Elasticsearch provides very extensive aggregation features that allow the aggregation over documents data.
While it supports schema definition, Elasticsearch allows the adding of data to the indexes without prior definition of its data structure, so we can consider it a schema-less database.
Elasticsearch and CAP Theorem
From the CAP theorem perspective, Elasticsearch can be classified as AP (Availability + Partition tolerance).
Which means in distributed mode, and for the availability side, it runs with no single point of failure. And for partition tolerance side, all the nodes of the cluster are equal in the role and can handle read/write at any time. So, if any one of the partitioned nodes fails, then joined back to the cluster after some time, it is able to recover the missed data to the current state.
elasticsearch does not give up on "Consistency" either. If it gives up on consistency then there will not be any document versioning and no index recovery.
So, Elasticsearch supports replications, fail-over, and eventual consistency and uses sharding as its partitioning strategy.(more on shards below).
Elastic Stack
Elasticsearch can run along side with other products from elastic-stack to provide wide range of capabilities and features , such as Kibana for data visualization and querying, Logstash for data transformations and loading, and many more others from Elasticsearch main website
2. Terminology
let us look at basics, but essential terms and definitions related to Elasticsearch
Index
it is the basic unit storage of Elasticsearch, it is akin to a database table. All write/read operations are done against an index. An index is identified by its unique name in Elasticsearch cluster.
Because Elasticsearch is a schema-less database, it is possible to start writing documents to non-existing indexes, and Elasticsearch will automatically create and define the index mapping for you, based on the document you submitted.
Elasticsearch indexes resolve to Lucene indexes on disk.
There is a tricky point about using an index as a verb or as a noun in Elasticsearch, that is worth mentioning:
- index as a noun: simply means the data structure of our documents like we just described above.
- index as a verb: it means the process of writing a document to an index (indexing).
Type
a deprecated concept that can be found in some resources, but it does not hold anymore, starting from version 6 and removed in version 7 and 8 currently. before version 6: an index can hold a collection of types, while a type was a collection of documents; we can think of it in compare to relational databases as: the index is a database schema, while a type was a table. In other words: an index holds types of documents.
Mapping
we can distinguish of mapping between as a noun or as a verb as follows:
mapping as a noun: it is the description of schema definition for an index, think of it like DDL (Data Definition Language) or data definition for an index.
mapping as a verb: is the art of defining an index structure before documents get indexed (inserted) to it.
Mapping is not required to begin writing a document as we will see later in the second part of this article. but it is common practice doing so, and in some cases, it is recommended for better performance.
Documents
documents simply are your data in JSON format, It is the same concept as other document-related databases because Elasticsearch is a document store itself.
So, documents are stored and retrieved as JSON objects, that consist of key-value pairs, in which the key is the name of a field, and the value is the content of that field.
In the next figure we presented one book document from books index as JSON object:
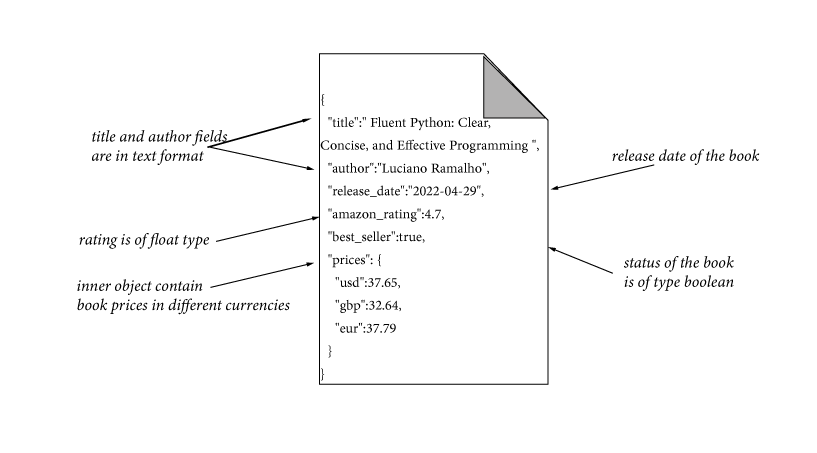
Each indexed document has a unique index (primary key) called '_id', and can be specified explicitly or by default from Elasticsearch.
Document fields can have a different structure, this is possible in Elasticsearch, but it is not recommended doing so.
Values in Elasticsearch must be in a specific data type, and by default, all fields in a document are indexed. but during the mapping, we can decide how indexing is applied to each field, based on the requirement and the use case of that index.
3. Elasticsearch Architecture
Node and Cluster
A Node is the single base machine/unit where Elasticsearch is running, and a cluster is a set of nodes that works together as a single node to provide a large range of capabilities and computing abilities.
As a client, to connect to an Elasticsearch cluster, you can connect to any one of the cluster nodes. In that sense, you can provide more than one node address in your connection parameters, in case one of the nodes fail.
the next figure shows different deployment types of Elasticsearch, from local standalone mode to large production clusters:

Shards
Elasticsearch keeps data in indexes, but an index is just a logical grouping not a physical storage. therefore, whenever an Elasticsearch index is created, that index will be composed of one or more shards.
Shards technically are physical instances of Apache Lucene, which take care of the physical storage and retrieval of our data. Elasticsearch manages these different instances, spreading data across them, and automatically balancing those instances across different nodes in the cluster.
Shards can be one of two roles: primary or replica. Primary shards are the ones holds the original data of the index, and can’t be changed once the index is created. therefore, when a large amount of data is split across several primary shards, a node can run a query on several Lucene instances in parallel, reducing the overall time of the job.
Replica shards or simply replicas, as the name suggests are just copies of primary shards. we can have one or more replica for each shard, or have no replica too (risk losing data ). the replication factor per shard is defined during Index mapping, and replicas can be added and removed on demand.
The shards are distributed across the cluster for availability and failover. On the other hand, replicas allow redundancy in the system. If one node fails, another node holding a replica can stand in place and complete the request.
The replica of a respective shard is not co-located on the same node as the shard ,as it defeats the purpose of redundancy.
Example scenario:
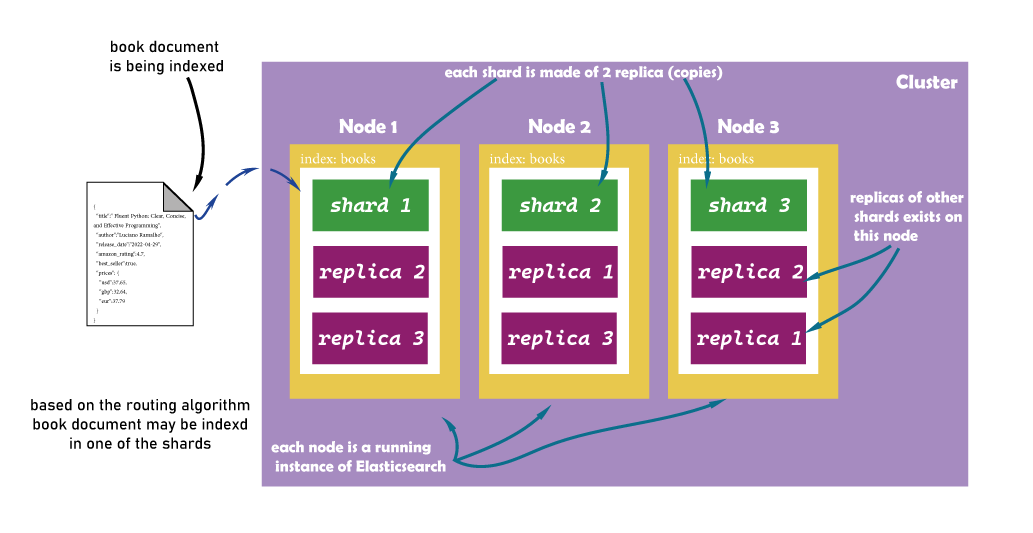
Each index can either exist on a single node or distributed across multiple nodes in the cluster. In our scenario design, we have a cluster of 3 nodes. To benefit for high availability, we create a books index with 3 shards and two replicas. so, every document we index (insert) will be stored as 3 copies: 1 in one of the primary shards, and 2 other copies as replicas.
As we know, replicas are a multiplier on the primary shards, so the total is calculated as:
total_of_shards = primary * (1+replicas).
The next figure shows our scenario design and how shards get distributed among the nodes in the cluster:
Inverted index
An inverted index at a high level is a data structure much like a dictionary or a hash map, with words as keys pointing to documents where these words are present. It consists of a set of unique words, and the frequency of those words occur across all the documents present in the index.
For each document that consists of full-text fields, the server creates the respective inverted indices. These inverted indexes is the key to faster retrieval of documents during the full-text search phase.
Lets say we have two documents with one text field named title. Every title field is backed up by an inverted index.
the next figure shows how Elasticsearch created an index from 2 documents with only one text field ‘title’ :
elasticsearch_inverted_index.png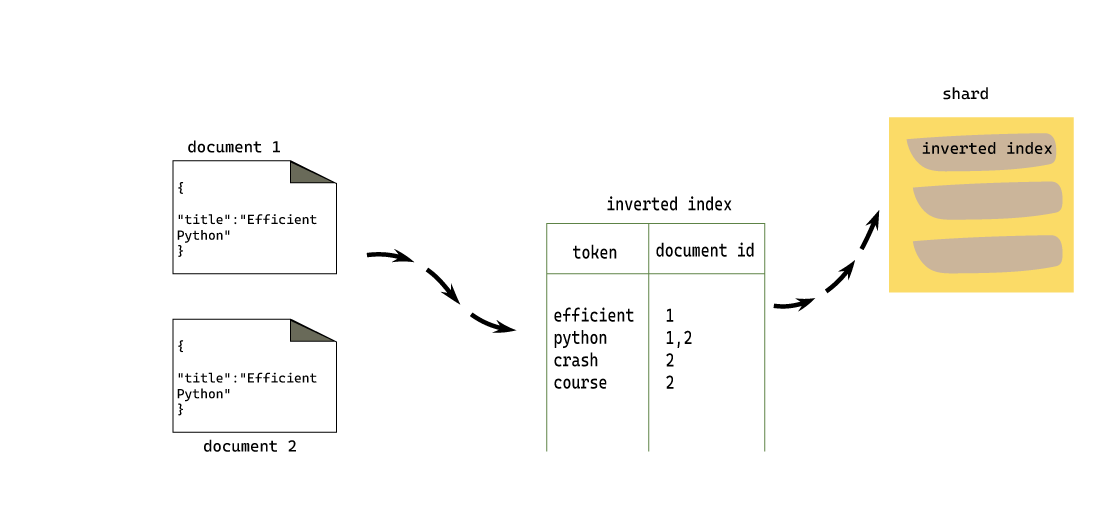
from the figure, the value of the title “Efficient Python” for example, is analyzed so that it gets tokenized and normalized into two words: efficient and python. The same process goes with document 2, and this is called the analysis process.
In Elasticsearch, the analysis process is a complex function accomplished by the Analyzer module.
Analyzer
This is the key to understanding how Elasticsearch uses Lucene to index documents. Once the document is submitted to Elasticsearch for indexing, the analysis process carried out by an analyzer module . it performs some operations on the body of the document before its terms are added to the inverted index.
An analyzer is built of three components:
- 0 or more character filters.
- exactly 1 tokenizer.
- 0 or more token filters.
Character Filtering:
is done by the aide of character filters, and these are used to preprocess the stream of characters before it passed to the next phase Tokenization. Character filters could change, add, or remove special characters from the string. for example, remove HTML tags from a document when indexing a web page.
Tokenizing:
done by tokenizer, which receive a stream of characters and splits them into arrays of tokens or words. There are many kinds of tokenizers, the easiest to think about for example a tokenizer is the one who split a sentence into words using white space as a delimiter.
Token Filtering:
is done by token filters, they create standards for each token before they are written into the inverted index. For example, remove stop words, and turn everything into lower/upper case.

So an Analyzer is an Elasticsearch package that contains these 3 components and uses them for analyzing or preprocessing a document before its tokens are written into an inverted index.
Elasticsearch comes with standard analyzer, however, it supports creating custom analyzers by combining these different subcomponents that form an analyzer
Routing Algorithm
Elasticsearch uses a routing algorithm to distribute the document to a certain shard when indexing. each one of the documents is stored into one and only one primary shard. Retrieving the same document will be easy too as the same routing function will be employed to find out the shard where that document belongs to.
Elasticsearch implement routing algorithm by using this simple formula to determine the appropriate shard for a document during indexing or searching:
shard_number = hash(id) % number_of_shards
The result of the routing function is a shard number. The routing function apply a hashing function on a unique id (generally document id) and finding out the remainder of the hash when divided with the number of shards. The documents are evenly distributed so there is no chance of one of the shards getting overloaded.
The routing algorithm function depends on the number_of_shards variable. which means once an index is created, we cannot change the number of shards. If it is possible or allowed to change primary shards settings ,for example from 2 to 3, then the routing function will give incorrect results for the existing records and data would not have been found. This is the reason why Elasticsearch don’t permit us to change the number of primary shards once the index is created.
Conclusion
search engines are different from databases in the way of how they store the data , and the indexes.
The Elasticsearch database analyzes the content JSON document and performs a series of functions using the analyzer, and the end of this operation is a set of terms that has reference to the document as inverted index .
Elasticsearch uses shards as horizontal partitions for high availability and redundancy over large data in multiples nodes cluster.
In the next part of this article we will get our hands dirty on some main CRUD operations that can be performed over documents in Elasticsearch .