Essentials Data models in InfluxDB
Publish Date: 2022-09-11

InfluxDB is an open source and popular time series database that was written in Go language, and it's first released in 2013 by Influxdata, to provide a platform optimized for fast, scalable and highly available storage and retrieval of time series data.
As time series data is different than data in relational databases, it needs a different design, element models and query language to get benefit of high precision and massive amount of workloads on it.
for that matter, in our article we will learn and define some terms and concepts related to time series data in InfluxDB.
Data Model - Terminology
Before moving further and working with InfluxDB data, it’s helpful to learn a few key concepts.
Organization
An InfluxDB organization is a workspace for a group of users. All dashboards, tasks, buckets, and users belong to an organization.
Bucket
All InfluxDB data is stored in a bucket. A bucket combines the concept of a database and a retention period policy( how long the data should be kept in the database before it gets discarded ).
In InfluxDB 2.4, databases and retention policies have been combined and replaced with buckets. So you don’t need to deal with the concept of databases explicitly, except in some specific cases.
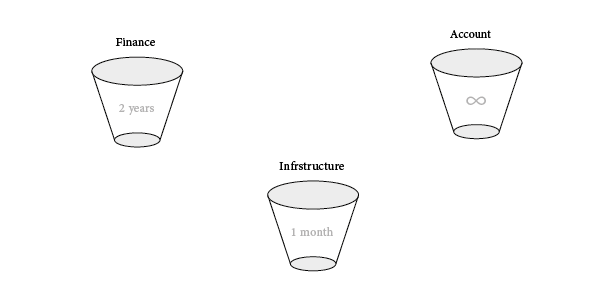
For example, a marketing team wants to identify accounts with the high cost and low revenues, they want to watch this ratio over time, so we would get revenue data from finance and cost data from infrastructure, then tie those together with an account bucket all within one organization.
So for that matter in our scenario, we would create infrastructure bucket with a 1-month retention policy, finance bucket with 2 years retention policy, and account bucket that keeps data forever.
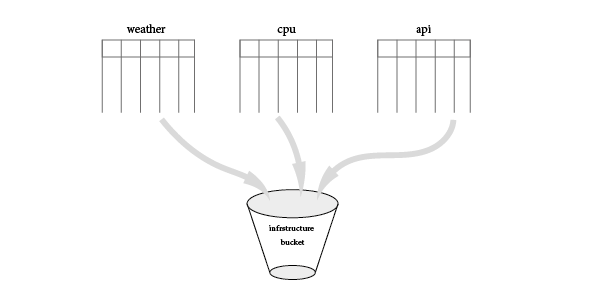
Measurement
it can be considered as a table, it is a container for fields, tags, and timestamps. Measurements are grouped into a bucket, for example in our infrastructure bucket we can create a measurement for Weather, CPU, and API where:
- Weather measurement: store data about temperature, humidity, wind speed, and direction
- CPU measurement: is good to store data about CPU utilization and CPU temperature
- API measurement: to store application performance metrics
| _time | _measurement | location | territory | _field | _value |
|---|---|---|---|---|---|
| 2022-09-09T21:09:59.420Z | weather | Algiers | East | temperature | 23.4 |
| 2022-09-09T19:16:00.000Z | weather | Algiers | East | wind_spead | 35.5 |
| 2022-09-09T19:36:00.000Z | weather | Algiers | East | wind_spead | 25.3 |
| 2022-09-09T21:09:59.420Z | weather | Algiers | West | temperature | 22.3 |
| 2022-09-09T19:36:00.000Z | weather | Algiers | West | wind_spead | 28.2 |
Timestamp
it is a first-class component of every measurement, this holds the date, and time value for a point in a measurement. It is like a primary key for every point in our measurement, and it is stored in the _time column.
InfluxDB formats timestamps show the date and time in RFC3339 UTC associated with data. Timestamp precision is important when you write data.
| _measurement | _field | _value | _time | location |
|---|---|---|---|---|
| weather | temperature | 37.34560618519155 | 2022-09-08T21:36:00.000Z | Algiers |
N.B: the underscore in some columns is just a convention that used in influxDB to identify important or reserved column names.
Field
fields are key-value pairs in which the key is a column name and the value is the data itself. Fields are required but not indexed in InfluxDB, which means if we perform a predicate on a field value will involve a full scan in a particular time range.
A field includes a field key stored in the _field column and a field value stored in the _value column. In our example a field key is temperature and the value is 22.4:
| _measurement | _field | _value | _time | location |
|---|---|---|---|---|
| weather | temperature | 22.4 | 2022-09-09T18:24:00.000Z | Algiers |
Fields set
A field set is a collection of fields in a point. For example, here we have a 2 field keys temperature and wind_speed :
| _measurement | _field | _value | _time | location |
|---|---|---|---|---|
| weather | temperature | 22.4 | 2022-09-09T18:24:00.000Z | Algiers |
| weather | wind_spead | 40.5 | 2022-09-09T18:24:00.000Z | Algiers |
from above data, the field set is temperature and wind_speed with its values :
temperature=22.4,wind_speed=40.5
Tags
they are like fields except they are optional, they are key-value pairs in which keys are called tag-keys and the values are called tag-values. Because tags are indexed, queries on tags are faster than queries on fields. This makes tags ideal for storing commonly-queried metadata.
| _measurement | _field | _value | _time | location | territory |
|---|---|---|---|---|---|
| weather | wind_spead | 35.5 | 2022-09-09T19:16:00.000Z | Algiers | East |
| weather | wind_spead | 25.3 | 2022-09-09T19:35:21.936Z | Algiers | East |
Tag set
The collection of tag key-value pairs on a point make up a tag set. our data examples include the following 2 tag sets:
location = Algiers, territory = East
location = Algiers, territory = West
Series
Now that you’re familiar with measurements, field sets, and tag sets, it’s time to discuss series keys and series.
A series key is a collection of points that share a measurement, tag set, and field key.
| _measurement | _field | _value | _time | location | territory |
|---|---|---|---|---|---|
| weather | wind_spead | 35.5 | 2022-09-09T19:16:00.000Z | Algiers | East |
| weather | wind_spead | 25.3 | 2022-09-09T19:35:21.936Z | Algiers | East |
| weather | wind_spead | 28.2 | 2022-09-09T19:36:00.000Z | Algiers | West |
A series includes timestamps and field values for a given series key. From our example data, here’s a series key and the corresponding series:
# series key
location=Algiers,territory=east wind_speed
# series
2022-09-09T19:16:00.000Z 35.5
2022-09-09T19:35:21.936Z 25.3
Point
if we are in relational databases, a point is a row while a measurement is a table. In InfluxDB a point is an instance within a measurement, and includes the series key, a field value, and a timestamp. For example, a single point from our data looks like this:
2022-09-09T19:16:00.000Z weather wind_speed 35.5 Algiers East
conclusion
InfluxDB is designed to store large volumes of time series data and quickly perform real-time analysis on that data. for that matter, the data model is different in many ways than in relational databases, and we get covered the most important aspect of it.