Learn CRUD Operations on Elasticsearch using Kibana
Publish Date: 2022-09-19

Whether you have structured or unstructured text, numerical data, or geospatial data, Elasticsearch efficiently stores and indexes it in a way that supports fast searches.
In our article today , we will learn how to perform CRUD operations on Elasticsearch which include create indexes , insert ,update , query as well as delete documents using Kibana console.
This article is a continuous from first part of Elasticsearch: Terminology and Architecture , make sure to take a look on it if you are unfamiliar with Elasticsearch before.
Install ElasticSearch and kibana
Installing Elasticsearch and Kibana can come in multiple flavours right from downloading the binaries, uncompressing and installing them on to your local machine in a traditional way, to using package manager, docker or even cloud. Choose appropriate flavour of installation for development to get started.
Elasticsearch and Kibana 8 comes by default with security enabled which makes little hard for beginners to get it right, but you can follow the instructions on official download Elasticsearch website page for steps required along with different options. And if you find any difficulties, leave me a comment below, and I will be happy to help you out.
If you already have an installation setup in your machine, then you can follow the rest of the article.
Working with Kibana
Elasticsearch is a document data store, so it is expecting the documents to be presented in JSON format. You can add data to Elasticsearch by sending JSON objects (documents) to Elasticsearch over HTTP. we use RESTful APIs to do just that. So any REST-based client (curl, Postman, Advanced REST client, HTTP module for JavaScript/NodeJS, browser addons, etc.) can help us talk to Elasticsearch via the API.
Fortunately, Elastic has a product that does exactly this and more: Kibana.
Kibana is a web application with a rich user interface, allowing users to index, query, visualize, and work with data. We will use in our demo article Kibana Dev Tools console to submit REST requests to Elasticsearch.
Launch elasticsearch in a terminal window:
elasticsearch
and also launch kibana in different terminal:
kibana
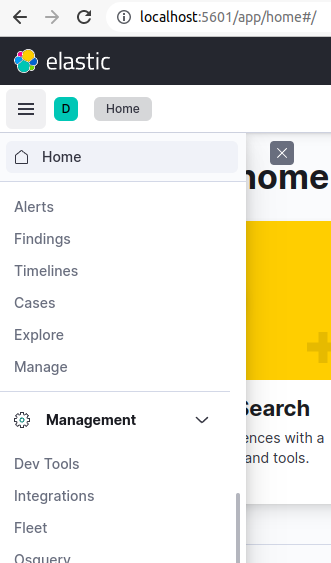
Go to the Kibana dashboard at http://localhost:5601, enter username and password , and in the top-left corner, you will find a main menu. Under this menu, you will find some links and sublinks. navigate to the Dev Tools link under Management, as figure shows:
then, you can execute queries in kibana editor console as the picture shows:
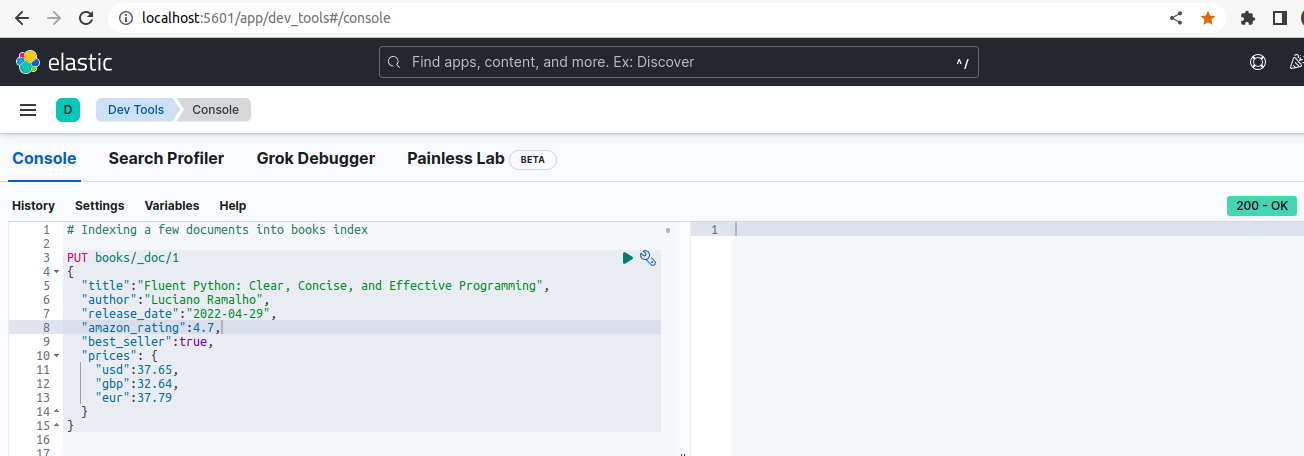
now, that we have our console is ready, let’s insert some document that we will work with.
1 - Insert Documents
The Elasticsearch API accepts a JSON document as the request body. To index our first document in the books store, the book we want to index should accompany this request.
we can use an HTTP PUT or POST on an endpoint. The next snippet inserts a document into books index.
PUT books/_doc/1
{
"title":"Fluent Python: Clear, Concise, and Effective Programming",
"author":"Luciano Ramalho",
"release_date":"2022-04-29",
"amazon_rating":4.7,
"best_seller":true,
"prices": {
"usd":37.65,
"gbp":32.64,
"eur":37.79
}
}
{
"_index": "books",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}
There are 5 parts to the request we just sent (PUT books/_doc/1) :
1. PUT method: PUT is a HTTP method that indicates we are sending a request to the server to create a resource (a book document in this case). Because Elasticsearch uses the HTTP protocol for its RESTful API invocations, you can use PUT, POST, GET, DELETE, and other standard HTTP methods in the request URL syntax.
2. The books index: The books is an index, which is a bucket for collecting all book documents. It is like a table in a relational database. the books index does not exist before, and because Elasticsearch in schema-less, then it will create it for us. Only book documents are stored in this books index.
3. The _doc endpoint: The _doc in the URL is the endpoint. This is a constant part of the path that’s associated with the operation being performed. In earlier versions of Elasticsearch (version < 7.0), the _doc’s place used to be filled up by a document’s mapping type. The mapping types were deprecated and _doc came to replace the document’s mapping types as a generic constant endpoint path in the URL.
So the _doc represents the endpoint name instead of the document type, and from ElasticSearch 8.x version, only _doc is supported, and it is a permanent part of the path for the document index, get, and delete APIs.
4. Document ID:: The number 1 in the URL represents the document’s ID. It is like a primary key for a record in a database. We will use this identifier to retrieve the document later on.
5. Request body: The body of the request is the JSON representation of the book data. Elasticsearch supports nested objects sent over in JSON’s nested objects format.
If the document is successfully inserted, this information shows in the right tab.
Index 2 more documents:
For our demo , we need more documents to index. Let’s insert two more documents and get them indexed using Kibana’s code editor. run the next 2 queries individually to have two more documents indexed :
PUT books/_doc/2
{
"title":"Python Crash Course A Hands-On Project-Based Introduction To Programming",
"author":"Eric Matthes",
"release_date":"2019-05-09",
"amazon_rating":4.8,
"best_seller":true,
"prices": {
"usd":19.95,
"gbp":22.53,
"eur":22.63
}
}
{
"_index": "books",
"_id": "2",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
PUT books/_doc/3
{
"title":"Python for Data Analysis, Data Wrangling with Pandas, NumPy, and IPython",
"author":"Wes Mckinney",
"release_date":"2017-11-03",
"amazon_rating":4.6,
"best_seller":true,
"prices": {
"usd":33.46,
"gbp":33.31,
"eur":28.85
}
}
{
"_index": "books",
"_id": "3",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
Now that we have some document in our books index, let’s do some searches and basic data retrieval.
2 - Finding Data
Let’s start with the basic one, which is counting how many documents we have. If we invoke the _count endpoint on the books index, we will get the number of documents in the books index:
GET books/_count
{
"count": 3,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
}
}
This should return a response as shown in the count field value, on the right side, indicating that there is 3 documents.
if we want to see the mapping of books index, just execute the GET method on the books index:
GET books
{
"books": {
"aliases": {},
"mappings": {
"properties": {
"amazon_rating": {
"type": "float"
},
"author": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"best_seller": {
"type": "boolean"
},
"prices": {
"properties": {
"eur": {
"type": "float"
},
"gbp": {
"type": "float"
},
"usd": {
"type": "float"
}
}
},
"release_date": {
"type": "date"
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "1",
"provided_name": "books",
"creation_date": "1663602090296",
"number_of_replicas": "1",
"uuid": "WW303qEbQ7WL0Nqbp_fnpQ",
"version": {
"created": "8040199"
}
}
}
}
}
we can also show the list of indices in our Elasticsearch databases along with the mappings available or created before, but because we're just getting started with Elasticsearch, we shall have only one index which is books as shown here:
GET _cat/indices
yellow open books WW303qEbQ7WL0Nqbp_fnpQ 1 1 3 0 13.3kb 13.3kb
Finding Documents
If we want to find or retrieve documents from our index, and depends on what we have, we can use different APIs or techniques:
If we know the document ID, we can use it to retrieve documents from the index. otherwise, if we don’t know the ID, then we have to use the _search API. For example if you want to retrieve a specific document, lets say document with ID 1, then issue a GET command using the ID as 1 as shown:
GET /books/_doc/1
{
"_index": "books",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"title": "Fluent Python: Clear, Concise, and Effective Programming",
"author": "Luciano Ramalho",
"release_date": "2022-04-29",
"amazon_rating": 4.7,
"best_seller": true,
"prices": {
"usd": 37.65,
"gbp": 32.64,
"eur": 37.79
}
}
}
The response has two pieces of information: the original document under the _source tag, and the metadata of this document (such as index, id, found, version etc.). That’s the basic way to find a document.
If you want to only return the original document content and get rid of metadata part, then simply replacing _doc with _source endpoint will do exactly that:
GET books/_source/1
{
"title": "Fluent Python: Clear, Concise, and Effective Programming",
"author": "Luciano Ramalho",
"release_date": "2022-04-29",
"amazon_rating": 4.7,
"best_seller": true,
"prices": {
"usd": 37.65,
"gbp": 32.64,
"eur": 37.79
}
}
Using the _search endpoint syntax, we can write a query to fetch all the books from our index:
GET /books/_search
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "books",
"_id": "1",
"_score": 1,
"_source": {
"title": "Fluent Python: Clear, Concise, and Effective Programming",
"author": "Luciano Ramalho",
"release_date": "2022-04-29",
"amazon_rating": 4.7,
"best_seller": true,
"prices": {
"usd": 37.65,
"gbp": 32.64,
"eur": 37.79
}
}
},
{
"_index": "books",
"_id": "2",
"_score": 1,
"_source": {
"title": "Python Crash Course A Hands-On Project-Based Introduction To Programming",
"author": "Eric Matthes",
"release_date": "2019-05-09",
"amazon_rating": 4.8,
"best_seller": true,
"prices": {
"usd": 19.95,
"gbp": 22.53,
"eur": 22.63
}
}
},
{
"_index": "books",
"_id": "3",
"_score": 1,
"_source": {
"title": "Python for Data Analysis, Data Wrangling with Pandas, NumPy, and IPython",
"author": "Wes Mckinney",
"release_date": "2017-11-03",
"amazon_rating": 4.6,
"best_seller": true,
"prices": {
"usd": 33.46,
"gbp": 33.31,
"eur": 28.85
}
}
}
]
}
}
the hits object indicate the number of results returned, and the hits array list contains the actual returned results. The actual book is enclosed in the _source object.
The syntax books/_search you just run is a short form of a special query named match_all query. Usually, a request body is added to the URL with a query clause:
GET books/_search
{
"query": {
"match_all": { }
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "books",
"_id": "1",
"_score": 1,
"_source": {
"title": "Fluent Python: Clear, Concise, and Effective Programming",
"author": "Luciano Ramalho",
"release_date": "2022-04-29",
"amazon_rating": 4.7,
"best_seller": true,
"prices": {
"usd": 37.65,
"gbp": 32.64,
"eur": 37.79
}
}
},
{
"_index": "books",
"_id": "2",
"_score": 1,
"_source": {
"title": "Python Crash Course A Hands-On Project-Based Introduction To Programming",
"author": "Eric Matthes",
"release_date": "2019-05-09",
"amazon_rating": 4.8,
"best_seller": true,
"prices": {
"usd": 19.95,
"gbp": 22.53,
"eur": 22.63
}
}
},
{
"_index": "books",
"_id": "3",
"_score": 1,
"_source": {
"title": "Python for Data Analysis, Data Wrangling with Pandas, NumPy, and IPython",
"author": "Wes Mckinney",
"release_date": "2017-11-03",
"amazon_rating": 4.6,
"best_seller": true,
"prices": {
"usd": 33.46,
"gbp": 33.31,
"eur": 28.85
}
}
}
]
}
}
from now on, this syntax is what we are going to use through the rest of our demo, along with its variations of course.
Full text search queries
full text queries involves doing searches on text fields using different techniques and criteria, that Elasticsearch offer to us.
For example, If we want to find all the titles authored by 'Ramalho', then we can use a match query with the criteria to search on an author field:
GET books/_search
{
"query": {
"match": {
"author": "Ramalho"
}
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "books",
"_id": "1",
"_score": 0.9808291,
"_source": {
"title": "Fluent Python: Clear, Concise, and Effective Programming",
"author": "Luciano Ramalho",
"release_date": "2022-04-29",
"amazon_rating": 4.7,
"best_seller": true,
"prices": {
"usd": 37.65,
"gbp": 32.64,
"eur": 37.79
}
}
}
]
}
}
The actual book result is enclosed in the _source object as we saw earlier.
you can change the match query to prefix query as to search for a shortened name (the author field value have to be in lowercase) :
GET books/_search
{
"query": {
"prefix": {
"author": "ramal"
}
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "books",
"_id": "1",
"_score": 1,
"_source": {
"title": "Fluent Python: Clear, Concise, and Effective Programming",
"author": "Luciano Ramalho",
"release_date": "2022-04-29",
"amazon_rating": 4.7,
"best_seller": true,
"prices": {
"usd": 37.65,
"gbp": 32.64,
"eur": 37.79
}
}
}
]
}
}
we can search for books that created by random author name 'Ramalho Mckinney' which is combination part from 2 author names, and find out what Elasticsearch will return to us:
GET books/_search
{
"query": {
"match": {
"author": "Ramalho Mckinney"
}
}
}
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 0.9808291,
"hits": [
{
"_index": "books",
"_id": "1",
"_score": 0.9808291,
"_source": {
"title": "Fluent Python: Clear, Concise, and Effective Programming",
"author": "Luciano Ramalho",
"release_date": "2022-04-29",
"amazon_rating": 4.7,
"best_seller": true,
"prices": {
"usd": 37.65,
"gbp": 32.64,
"eur": 37.79
}
}
},
{
"_index": "books",
"_id": "3",
"_score": 0.9808291,
"_source": {
"title": "Python for Data Analysis, Data Wrangling with Pandas, NumPy, and IPython",
"author": "Wes Mckinney",
"release_date": "2017-11-03",
"amazon_rating": 4.6,
"best_seller": true,
"prices": {
"usd": 33.46,
"gbp": 33.31,
"eur": 28.85
}
}
}
]
}
}
however this query use the 'OR' operator, that means it try to find books which the author either is 'Ramalho' OR 'Mckinney', but what we want is to get books in which the author name contain both names. and for that, we have to use the 'AND' operator like that:
GET books/_search
{
"query": {
"match": {
"author": {
"query": "Ramalho Mckinney",
"operator": "AND"
}
}
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 0,
"relation": "eq"
},
"max_score": null,
"hits": []
}
}
of course no result get back (hits value = 0), because there is no author of that full name has books in our index.
as we're going to search with more advanced queries, we need some data with more fields. However, instead of inserting individual documents, this time we will use the _bulk API to insert multiples documents in one go .
Indexing more documents using the _bulk API
our new data we want to insert include 3 more fields, comment which is like a comment or short abstract on what the book is about, edition, and tags which is nested object array.
Here we use the POST method,the syntax is different from it was in PUT method, and every 2 lines correspond to one document where the first line include metadata about index and document, and the second line is about the data itself.
Note: this insert will override the existing documents in books index.
POST _bulk
{"index":{"_index":"books","_id":"1"}}
{"title": "Fluent Python","author": "Luciano Ramalho","edition": 2, "comment": "Clear, Concise, and Effective Programming","amazon_rating": 4.7,"release_date": "2022-05-10","tags": ["Object-Oriented Design", "Python Programming", "Computer Programming Languages"]}
{"index":{"_index":"books","_id":"2"}}
{"title": "Python crash Course","author": "Eric Matthes", "edition": 3,"comment": "A Hands-On Project-Based Introduction To Programming", "amazon_rating": 4.7, "release_date": "2023-01-10", "tags": ["Python Programming", "Computer Programming Languages", "Software Development"]}
{"index":{"_index":"books","_id":"3"}}
{"title": "Python for Data Analysis", "author": "Wes Mckinney","edition": 3,"comment": "Data Wrangling with Pandas, NumPy, and Jupyter","amazon_rating": 5,"release_date": "2022-09-20","tags": ["Database Storage & Design", "Data Mining", "Data Processing"]}
{"index":{"_index":"books","_id":"4"}}
{"title": "Python for Data Analysis", "author": "William Mckinney","edition": 2,"comment": "Data Wrangling with Pandas, NumPy, and IPython","amazon_rating": 4.6,"release_date": "2017-11-14","tags": ["Data Modeling & Design","Data Processing", "Python Programming"]}
{"index":{"_index":"books","_id":"5"}}
{"title": "Python Data Analysis", "author": "Avinash Navlani , Armando Fandango , et al","edition": 3,"comment": "Perform data collection, data processing, wrangling, visualization, and model building using Python","amazon_rating": 4.7,"release_date": "2021-02-05","tags": ["Data Modeling & Design","Data Processing", "Python Programming"]}
{"index":{"_index":"books","_id":"6"}}
{"title": "Python Network Programming","author": "Abhishek Ratan, Eric Chou ,Pradeeban Kathiravelu, Dr. M. O. Faruque Sarker","edition": 1,"comment": "Conquer all your networking challenges with the powerful Python language","amazon_rating": 4.5,"release_date": "2019-01-31","tags": ["Computer Networking", "Computer Networks", "Computer Network Security"]}
{"index":{"_index":"books","_id":"7"}}
{"title": "Tiny Python Projects","author": "Ken Youens-Clak","edition":6, "comment": "21 small fun projects for Python beginners designed to build programming skill, teach new algorithms and techniques, and introduce software testing","amazon_rating": 4.6,"release_date": "2020-09-01","tags": ["Software Design & Engineering", "Object-Oriented Design","Software Testing"]}
{"index":{"_index":"books","_id":"8"}}
{"title": "Serious Python","author": "Julien Danjou","edition": 2,"comment": "Black-Belt Advice on Deployment, Scalability, Testing, and More","amazon_rating": 4.7,"release_date": "2018-12-27","tags": ["Functional Software Programming","Software Testing" ,"Computer Hacking"]}
{"index":{"_index":"books","_id":"9"}}
{"title": "Automate the Boring Stuff with Python","author": "Al Sweigart","edition": 2,"comment": "Practical Programming for Total Beginners","amazon_rating": 4.7,"release_date": "2019-11-12","tags": ["Microsoft Programming", "Python Programming", "Computer Programming Languages"]}
{"index":{"_index":"books","_id":"10"}}
{"title": "Python in a Nutshell","author": "Alex Martelli, Anna Martelli Ravenscroft, Steve Holden, and Paul McGuire","edition": 3,"comment": "A Desktop Quick Reference for python language","amazon_rating": 4.5,"release_date": "2017-05-16","tags": ["Functional Software Programming", "Object-Oriented Software Design", "Object-Oriented Design"]}
{
"took": 65,
"errors": false,
"items": [
{
"index": {
"_index": "books",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1,
"status": 200
}
},
{
"index": {
"_index": "books",
"_id": "2",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 4,
"_primary_term": 1,
"status": 200
}
},
{
"index": {
"_index": "books",
"_id": "3",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 5,
"_primary_term": 1,
"status": 200
}
},
{
"index": {
"_index": "books",
"_id": "4",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 6,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "books",
"_id": "5",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 7,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "books",
"_id": "6",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 8,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "books",
"_id": "7",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 9,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "books",
"_id": "8",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 10,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "books",
"_id": "9",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 11,
"_primary_term": 1,
"status": 201
}
},
{
"index": {
"_index": "books",
"_id": "10",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 12,
"_primary_term": 1,
"status": 201
}
}
]
}
once the data inserted successfully, you should receive an acknowledgment as show in the result side.
search across multiples fields
so far, we have been searching across only one field, if we want to expand our Searching across multiple fields, then we can use a multi_match query. In our next snippet , we are trying to find books that contain word: python across 2 fields, title and comment:
GET books/_search
{
"query": {
"multi_match": {
"query": "python",
"fields": ["title","comment"]
}
}
}
{
"took": 647,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 10,
"relation": "eq"
},
"max_score": 0.9869959,
"hits": [
{
"_index": "books",
"_id": "10",
"_score": 0.9869959,
"_source": {
"title": "Python in a Nutshell",
"author": "Alex Martelli, Anna Martelli Ravenscroft, Steve Holden, and Paul McGuire",
"edition": 3,
"comment": "A Desktop Quick Reference for python language",
"amazon_rating": 4.5,
"release_date": "2017-05-16",
"tags": [
"Functional Software Programming",
"Object-Oriented Software Design",
"Object-Oriented Design"
]
}
},
{
"_index": "books",
"_id": "6",
"_score": 0.85906065,
"_source": {
"title": "Python Network Programming",
"author": "Abhishek Ratan, Eric Chou ,Pradeeban Kathiravelu, Dr. M. O. Faruque Sarker",
"edition": 1,
"comment": "Conquer all your networking challenges with the powerful Python language",
"amazon_rating": 4.5,
"release_date": "2019-01-31",
"tags": [
"Computer Networking",
"Computer Networks",
"Computer Network Security"
]
}
},
{
"_index": "books",
"_id": "5",
"_score": 0.7907307,
"_source": {
"title": "Python Data Analysis",
"author": "Avinash Navlani , Armando Fandango , et al",
"edition": 3,
"comment": "Perform data collection, data processing, wrangling, visualization, and model building using Python",
"amazon_rating": 4.7,
"release_date": "2021-02-05",
"tags": [
"Data Modeling & Design",
"Data Processing",
"Python Programming"
]
}
},
{
"_index": "books",
"_id": "7",
"_score": 0.5823051,
"_source": {
"title": "Tiny Python Projects",
"author": "Ken Youens-Clak",
"edition": 6,
"comment": "21 small fun projects for Python beginners designed to build programming skill, teach new algorithms and techniques, and introduce software testing",
"amazon_rating": 4.6,
"release_date": "2020-09-01",
"tags": [
"Software Design & Engineering",
"Object-Oriented Design",
"Software Testing"
]
}
},
{
"_index": "books",
"_id": "1",
"_score": 0.055943683,
"_source": {
"title": "Fluent Python",
"author": "Luciano Ramalho",
"edition": 2,
"comment": "Clear, Concise, and Effective Programming",
"amazon_rating": 4.7,
"release_date": "2022-05-10",
"tags": [
"Object-Oriented Design",
"Python Programming",
"Computer Programming Languages"
]
}
},
{
"_index": "books",
"_id": "8",
"_score": 0.055943683,
"_source": {
"title": "Serious Python",
"author": "Julien Danjou",
"edition": 2,
"comment": "Black-Belt Advice on Deployment, Scalability, Testing, and More",
"amazon_rating": 4.7,
"release_date": "2018-12-27",
"tags": [
"Functional Software Programming",
"Software Testing",
"Computer Hacking"
]
}
},
{
"_index": "books",
"_id": "2",
"_score": 0.048872154,
"_source": {
"title": "Python crash Course",
"author": "Eric Matthes",
"edition": 3,
"comment": "A Hands-On Project-Based Introduction To Programming",
"amazon_rating": 4.7,
"release_date": "2023-01-10",
"tags": [
"Python Programming",
"Computer Programming Languages",
"Software Development"
]
}
},
{
"_index": "books",
"_id": "3",
"_score": 0.04338775,
"_source": {
"title": "Python for Data Analysis",
"author": "Wes Mckinney",
"edition": 3,
"comment": "Data Wrangling with Pandas, NumPy, and Jupyter",
"amazon_rating": 5,
"release_date": "2022-09-20",
"tags": [
"Database Storage & Design",
"Data Mining",
"Data Processing"
]
}
},
{
"_index": "books",
"_id": "4",
"_score": 0.04338775,
"_source": {
"title": "Python for Data Analysis",
"author": "William Mckinney",
"edition": 2,
"comment": "Data Wrangling with Pandas, NumPy, and IPython",
"amazon_rating": 4.6,
"release_date": "2017-11-14",
"tags": [
"Data Modeling & Design",
"Data Processing",
"Python Programming"
]
}
},
{
"_index": "books",
"_id": "9",
"_score": 0.035434797,
"_source": {
"title": "Automate the Boring Stuff with Python",
"author": "Al Sweigart",
"edition": 2,
"comment": "Practical Programming for Total Beginners",
"amazon_rating": 4.7,
"release_date": "2019-11-12",
"tags": [
"Microsoft Programming",
"Python Programming",
"Computer Programming Languages"
]
}
}
]
}
}
We can use another type of query named match_phrase query for searching a long list of words as a phrase. In other words, search for a sequence of words, exactly in that order. for example when you search for exact sequence words in title or in comment:
GET books/_search
{
"query": {
"match_phrase": {
"comment": "Reference for python"
}
}
}
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 4.4516406,
"hits": [
{
"_index": "books",
"_id": "10",
"_score": 4.4516406,
"_source": {
"title": "Python in a Nutshell",
"author": "Alex Martelli, Anna Martelli Ravenscroft, Steve Holden, and Paul McGuire",
"edition": 3,
"comment": "A Desktop Quick Reference for python language",
"amazon_rating": 4.5,
"release_date": "2017-05-16",
"tags": [
"Functional Software Programming",
"Object-Oriented Software Design",
"Object-Oriented Design"
]
}
}
]
}
}
we can set match_phrase with a slop parameter if we expect or have some missing words in our searching phrase . Here we expect that one word ( 'for' ) is missing in our search phrase, so the slop parameter has a value of one:
GET books/_search
{
"query": {
"match_phrase": {
"comment": {
"query": "Reference python",
"slop": 1
}
}
}
}
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.127492,
"hits": [
{
"_index": "books",
"_id": "10",
"_score": 2.127492,
"_source": {
"title": "Python in a Nutshell",
"author": "Alex Martelli, Anna Martelli Ravenscroft, Steve Holden, and Paul McGuire",
"edition": 3,
"comment": "A Desktop Quick Reference for python language",
"amazon_rating": 4.5,
"release_date": "2017-05-16",
"tags": [
"Functional Software Programming",
"Object-Oriented Software Design",
"Object-Oriented Design"
]
}
}
]
}
}
we can search for phrases matching with a prefix, lets say for instance we want to look for all title books that starts with 'python data' :
GET books/_search
{
"query": {
"match_phrase_prefix": {
"title": "python data"
}
}
}
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.2519045,
"hits": [
{
"_index": "books",
"_id": "5",
"_score": 1.2519045,
"_source": {
"title": "Python Data Analysis",
"author": "Avinash Navlani , Armando Fandango , et al",
"edition": 3,
"comment": "Perform data collection, data processing, wrangling, visualization, and model building using Python",
"amazon_rating": 4.7,
"release_date": "2021-02-05",
"tags": [
"Data Modeling & Design",
"Data Processing",
"Python Programming"
]
}
}
]
}
}
the result returns all the books that contains a words 'python data' in the title field.
Fuzzy query for forgiveness mistakes
we can use a fuzzy query if we might expect making a spelling mistake . For example here we search for a keyword datta , but our intention was to search for data. We set fuzziness as 1 because we expect one single letter change (here we have one character unnecessary : t ) as required to match the subject:
GET books/_search
{
"query": {
"fuzzy": {
"title": {
"value": "datta",
"fuzziness": 1
}
}
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 0.9022743,
"hits": [
{
"_index": "books",
"_id": "5",
"_score": 0.9022743,
"_source": {
"title": "Python Data Analysis",
"author": "Avinash Navlani , Armando Fandango , et al",
"edition": 3,
"comment": "Perform data collection, data processing, wrangling, visualization, and model building using Python",
"amazon_rating": 4.7,
"release_date": "2021-02-05",
"tags": [
"Data Modeling & Design",
"Data Processing",
"Python Programming"
]
}
},
{
"_index": "books",
"_id": "3",
"_score": 0.8010216,
"_source": {
"title": "Python for Data Analysis",
"author": "Wes Mckinney",
"edition": 3,
"comment": "Data Wrangling with Pandas, NumPy, and Jupyter",
"amazon_rating": 5,
"release_date": "2022-09-20",
"tags": [
"Database Storage & Design",
"Data Mining",
"Data Processing"
]
}
},
{
"_index": "books",
"_id": "4",
"_score": 0.8010216,
"_source": {
"title": "Python for Data Analysis",
"author": "William Mckinney",
"edition": 2,
"comment": "Data Wrangling with Pandas, NumPy, and IPython",
"amazon_rating": 4.6,
"release_date": "2017-11-14",
"tags": [
"Data Modeling & Design",
"Data Processing",
"Python Programming"
]
}
}
]
}
}
Term level queries for unstructured data:
while structured data like text fields gets analyzed, the unstructured data like dates and numbers are stored as it is. So we can use a term query to exactly specific value for our search field.
term query
Let's say for example we want to get the second edition of books from our store, the query should be as follows:
GET books/_search
{
"query": {
"term": {
"edition": {
"value": 2
}
}
}
}
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "books",
"_id": "1",
"_score": 1,
"_source": {
"title": "Fluent Python",
"author": "Luciano Ramalho",
"edition": 2,
"comment": "Clear, Concise, and Effective Programming",
"amazon_rating": 4.7,
"release_date": "2022-05-10",
"tags": [
"Object-Oriented Design",
"Python Programming",
"Computer Programming Languages"
]
}
},
{
"_index": "books",
"_id": "4",
"_score": 1,
"_source": {
"title": "Python for Data Analysis",
"author": "William Mckinney",
"edition": 2,
"comment": "Data Wrangling with Pandas, NumPy, and IPython",
"amazon_rating": 4.6,
"release_date": "2017-11-14",
"tags": [
"Data Modeling & Design",
"Data Processing",
"Python Programming"
]
}
},
{
"_index": "books",
"_id": "8",
"_score": 1,
"_source": {
"title": "Serious Python",
"author": "Julien Danjou",
"edition": 2,
"comment": "Black-Belt Advice on Deployment, Scalability, Testing, and More",
"amazon_rating": 4.7,
"release_date": "2018-12-27",
"tags": [
"Functional Software Programming",
"Software Testing",
"Computer Hacking"
]
}
},
{
"_index": "books",
"_id": "9",
"_score": 1,
"_source": {
"title": "Automate the Boring Stuff with Python",
"author": "Al Sweigart",
"edition": 2,
"comment": "Practical Programming for Total Beginners",
"amazon_rating": 4.7,
"release_date": "2019-11-12",
"tags": [
"Microsoft Programming",
"Python Programming",
"Computer Programming Languages"
]
}
}
]
}
}
if you look at score result, you should find that it has a value of 1. simply because it is not related to relevancy , it is either exist or not.
range query
another type of queries is the range query which used to fetch data fields of type range. Let's say we want to get books with rating between 4.7 and 5. So our range query will be like that:
GET books/_search
{
"query": {
"range": {
"amazon_rating": {
"gte": 4.6,
"lte": 5
}
}
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 6,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "books",
"_id": "1",
"_score": 1,
"_source": {
"title": "Fluent Python",
"author": "Luciano Ramalho",
"edition": 2,
"comment": "Clear, Concise, and Effective Programming",
"amazon_rating": 4.7,
"release_date": "2022-05-10",
"tags": [
"Object-Oriented Design",
"Python Programming",
"Computer Programming Languages"
]
}
},
{
"_index": "books",
"_id": "2",
"_score": 1,
"_source": {
"title": "Python crash Course",
"author": "Eric Matthes",
"edition": 3,
"comment": "A Hands-On Project-Based Introduction To Programming",
"amazon_rating": 4.7,
"release_date": "2023-01-10",
"tags": [
"Python Programming",
"Computer Programming Languages",
"Software Development"
]
}
},
{
"_index": "books",
"_id": "3",
"_score": 1,
"_source": {
"title": "Python for Data Analysis",
"author": "Wes Mckinney",
"edition": 3,
"comment": "Data Wrangling with Pandas, NumPy, and Jupyter",
"amazon_rating": 5,
"release_date": "2022-09-20",
"tags": [
"Database Storage & Design",
"Data Mining",
"Data Processing"
]
}
},
{
"_index": "books",
"_id": "5",
"_score": 1,
"_source": {
"title": "Python Data Analysis",
"author": "Avinash Navlani , Armando Fandango , et al",
"edition": 3,
"comment": "Perform data collection, data processing, wrangling, visualization, and model building using Python",
"amazon_rating": 4.7,
"release_date": "2021-02-05",
"tags": [
"Data Modeling & Design",
"Data Processing",
"Python Programming"
]
}
},
{
"_index": "books",
"_id": "8",
"_score": 1,
"_source": {
"title": "Serious Python",
"author": "Julien Danjou",
"edition": 2,
"comment": "Black-Belt Advice on Deployment, Scalability, Testing, and More",
"amazon_rating": 4.7,
"release_date": "2018-12-27",
"tags": [
"Functional Software Programming",
"Software Testing",
"Computer Hacking"
]
}
},
{
"_index": "books",
"_id": "9",
"_score": 1,
"_source": {
"title": "Automate the Boring Stuff with Python",
"author": "Al Sweigart",
"edition": 2,
"comment": "Practical Programming for Total Beginners",
"amazon_rating": 4.7,
"release_date": "2019-11-12",
"tags": [
"Microsoft Programming",
"Python Programming",
"Computer Programming Languages"
]
}
}
]
}
}
there is other term level queries that we didn’t cover such as exists, regexp, ids... as the space don’t allow to. Feel free to check them Later on.
so far we have been using simple queries, but in real world you will have to use more complex queries on multiples fields, and that’s what we are going to cover next.
Compound Queries
for more complex scenarios, Compound queries use a combination of individual queries (also called leaf queries) to build and make robust queries . The queries in this group are:
- bool query
- boosting query
- constant_score query
- dis_max query
- function_score query
because it is more popular and most commonly used ,we will cover a simple use case example using a bool query. This query use a combination of multiple leaf queries based on Boolean condition, and it uses result from 1 or more clauses such as must, should, must_not, or filter clauses.
The must and should clauses have their scores combined — the more matching clauses, the better — while the must_not and filter clauses are executed in filter context.
Lets say for instant that we want to get books from 'Ramalho' only if the rating is 4.7 or more , so the author must be 'Ramalho' (must → much clause) and the rating must not less than 4.7 (must not → range clause) :
the next snippet shows how to get that query :
GET books/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"author": "ramalho"
}
}
],
"must_not": [
{
"range": {
"amazon_rating": {
"lt": 4.7
}
}
}
]
}
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.5358205,
"hits": [
{
"_index": "books",
"_id": "1",
"_score": 2.5358205,
"_source": {
"title": "Fluent Python",
"author": "Luciano Ramalho",
"edition": 2,
"comment": "Clear, Concise, and Effective Programming",
"amazon_rating": 4.7,
"release_date": "2022-05-10",
"tags": [
"Object-Oriented Design",
"Python Programming",
"Computer Programming Languages"
]
}
}
]
}
}
as as expected ,the result is one book that exist in our books index and fit the query criteria.
should clause
In other hand, the should clause act like an OR operator, so it affects the score if it matches, otherwise it does not affect the result. So lets bump and raise up the score result of previous query by finding books that match tags = programming in our query. The query should be like this (here we use a compact query style to make more easy to follow):
GET books/_search
{
"query": {
"bool": {
"must": [{
"match": {"author": "ramalho"}
}],
"must_not":[{
"range":{"amazon_rating":{"lt":4.7}}
}],
"should": [{
"match": {"tags": "programming"}
}]
}
}
}
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 3.0527425,
"hits": [
{
"_index": "books",
"_id": "1",
"_score": 3.0527425,
"_source": {
"title": "Fluent Python",
"author": "Luciano Ramalho",
"edition": 2,
"comment": "Clear, Concise, and Effective Programming",
"amazon_rating": 4.7,
"release_date": "2022-05-10",
"tags": [
"Object-Oriented Design",
"Python Programming",
"Computer Programming Languages"
]
}
}
]
}
}
you should notice in score difference from previous run, after using should clause, it was 2.53, and it is now 3.05
filter clause
The filter clause work like the must clause, except it doesn’t affect score, and it’s purpose is to filter out result query. And for the records that doesn’t match the criteria filter, they will get dropped. For example lets filter out the result to only return the books that released after 2022-01-01, we add the filter clause to our previous query like that:
GET books/_search
{
"query": {
"bool": {
"must": [{
"match": {"author": "Ramalho"}
}],
"must_not":[{
"range":{"amazon_rating":{"lt":4.7}}
}],
"should": [{
"match": {"tags": "Programming"}
}],
"filter":[{
"range":{"release_date":{"gte": "2022-01-01"}}
}]
}
}
}
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 3.0527425,
"hits": [
{
"_index": "books",
"_id": "1",
"_score": 3.0527425,
"_source": {
"title": "Fluent Python",
"author": "Luciano Ramalho",
"edition": 2,
"comment": "Clear, Concise, and Effective Programming",
"amazon_rating": 4.7,
"release_date": "2022-05-10",
"tags": [
"Object-Oriented Design",
"Python Programming",
"Computer Programming Languages"
]
}
}
]
}
}
we can add more term queries inside those clauses to get more accurate and sophisticated results.
But for now, lets move from querying documents to see how to update them.
3 - Update Documents
Update could mean: adding fields, updating existing fields or updating the hole document.
We can update documents by using _update API provided by Elasticsearch, which executes the set of update operations on the same shard, and thus avoiding network traffic between client and server . The _update API has two types variant:
- _update API :to update a single document.
- _update_by_query API : to modify multiples documents in one step.
_update API
a - add new field
lets add a new field to an existing book document using the _update API. This query adds format and publisher fields to our book document with ID=3. The new fields are wrapped in a doc object as the API expects in that manner:
POST books/_update/3
{
"doc": {
"version":["paperback","kindle","paper"],
"publisher":"OReilly Media"
}
}
{
"_index": "books",
"_id": "3",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 13,
"_primary_term": 1
}
when you change any field or made any modifications on a document, a version field in a document metadata get increased, and that how you can track changes on documents. you can see that in result tab on the right side. For example in the query we just run, the version is 3 , because when we insert using _bulk insert, it increased from 1 to 2, and when we update the document now, it increases the version to 3 .
For example, retrieve book document with id 3, and check version it is 3 now, as well as the new fields we just insert under source object:
GET books/_doc/3
{
"_index": "books",
"_id": "3",
"_version": 3,
"_seq_no": 13,
"_primary_term": 1,
"found": true,
"_source": {
"title": "Python for Data Analysis",
"author": "Wes Mckinney",
"edition": 3,
"comment": "Data Wrangling with Pandas, NumPy, and Jupyter",
"amazon_rating": 5,
"release_date": "2022-09-20",
"tags": [
"Database Storage & Design",
"Data Mining",
"Data Processing"
],
"publisher": "OReilly Media",
"version": [
"paperback",
"kindle",
"paper"
]
}
}
b - modify existing field
if we want to modify an existing field, we just have to provide the new value to the field in a doc object as we did with the previous query. For example to change the release date from current value : 2022-09-20 to the new one which is 2022-09-21, we can do so using the following query:
POST books/_update/3
{
"doc": {
"release_date" : "2022-09-21"
}
}
{
"_index": "books",
"_id": "3",
"_version": 4,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 14,
"_primary_term": 1
}
as you can see, this increase document version to value of 4.
c - update entire document
in our bulk insert earlier, we made a mistake intentionally , where we insert the document with the ID=2 . the edition 3 for that document book is not yet released (will be released in 2023-01-10).
to correct that, we will replace this 3rd edition book document with the 2nd edition, which is available since 2019-05-03 by the author 'Eric Matthes' .
therefore, to replace a document with the ID=2, we can use the PUT request on that document as follows:
PUT books/_doc/2
{
"title": "Python crash Course",
"author": "Eric Matthes",
"edition": 2,
"comment": "A Hands-On Project-Based Introduction To Programming",
"amazon_rating": 4.7,
"release_date": "2019-05-03",
"tags": [
"Open Source Programming",
"Python Computer Programming",
"Software Development"
]
}
{
"_index": "books",
"_id": "2",
"_version": 3,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 15,
"_primary_term": 1
}
the previous query is just overriding the document.
_update_by_query API
Sometimes we might want to update a set of documents based on specific criteria - for example for all books whose rating is above 4.6, mark them as popular (doesn't mean much in reality, but let us stick with it for now, and you can develop more scenarios later on). We can run a query to search for such a set of documents and apply the updates on those by using the _update_by_query endpoint.
Say, we need to update all the books with the amazon_rating is greater than 4.6, and insert a field on them with value popular = true, using the script block with context object (ctx). The next snippet will do exactly that:
POST books/_update_by_query
{
"query": {
"range": {
"amazon_rating": {
"gt": 4.6
}
}
},
"script": {
"inline": "ctx._source.popular = true",
"lang": "painless"
}
}
#! Deprecated field [inline] used, expected [source] instead
{
"took": 94,
"timed_out": false,
"total": 6,
"updated": 6,
"deleted": 0,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}
In the snippet, the match query executes first to fetch all the books where amazon_rating is greater than 4.6.
When the match query returns its results, a script executes to add a field popular that contain a value 'true' . and as we can see, 6 documents get affected by the query.
for example, when we query document with ID=3, this is how it looks like (notice that the version became now 5):
GET books/_doc/3
{
"_index": "books",
"_id": "3",
"_version": 5,
"_seq_no": 20,
"_primary_term": 1,
"found": true,
"_source": {
"release_date": "2022-09-21",
"author": "Wes Mckinney",
"edition": 3,
"publisher": "OReilly Media",
"comment": "Data Wrangling with Pandas, NumPy, and Jupyter",
"amazon_rating": 5,
"title": "Python for Data Analysis",
"version": [
"paperback",
"kindle",
"paper"
],
"popular": true,
"tags": [
"Database Storage & Design",
"Data Mining",
"Data Processing"
]
}
}
4 - Delete Documents
when deleting documents, we can either use the ID of the document, or using a query to delete multiples documents by specifying filter criteria.
delete by ID
we can invoke the HTTP DELETE method, and construct the URL by specifying the index, the _doc endpoint, and the ID of the document. For example, we can invoke the query to delete the document with the ID=3 from the books index:
DELETE books/_doc/3
{
"_index": "books",
"_id": "3",
"_version": 6,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 22,
"_primary_term": 1
}
The response received from the server on the right side panel, indicates that the document was deleted successfully , and this also increase version to 6.
you can check if the book with ID=3 is still exist, if not , found is false:
GET books/_doc/3
{
"_index": "books",
"_id": "3",
"found": false
}
Delete by query
similar to _update_by_query, we can delete by query. Let’s say we want to delete all the books that are released before 2020 , we would write the query like that:
POST books/_delete_by_query
{
"query":{
"range": {
"release_date": {
"lt": "2020-01-01"
}
}
}
}
{
"took": 15,
"timed_out": false,
"total": 6,
"deleted": 6,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}
Now, if we decide to delete a whole set of documents from our books index, we can by using the match_all query. The next snippet demonstrates this operation:
POST books/_delete_by_query
{
"query":{
"match_all":{}
}
}
{
"took": 14,
"timed_out": false,
"total": 3,
"deleted": 3,
"batches": 1,
"version_conflicts": 0,
"noops": 0,
"retries": {
"bulk": 0,
"search": 0
},
"throttled_millis": 0,
"requests_per_second": -1,
"throttled_until_millis": 0,
"failures": []
}
Delete Index
now our index is empty, we can delete the books index from the Elasticsearch database as well:
DELETE books
{
"acknowledged": true
}
if returned result like the one in the result tab, that means a successful deletion.
you can check the list of indices(indexes and mappings) to see if the Elasticsearch database is empty:
GET _cat/indices
Conclusion
As we reach the end of our article, and probably this could be so much for one article, but it is enough to get a high level overview of the CRUD operations on Elasticsearch with Kibana, and I hope you are now a little familiar with the basics and query syntax of Elasticsearch , the most popular among the document search databases.