Spark Structured Streaming with CSV files
Publish Date: 2022-10-21

Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. You can express your streaming computation the same way you would express a batch computation on static data. The Spark SQL engine will take care of running it incrementally and continuously and updating the final result as streaming data continues to arrive.
In our article today we will see how to read streaming data from folder that contain csv files, and process it through spark using python and show result out to console .
Getting started
The first step is to clarify more our scenario.We will use cars dataset from this : kaggle link , when you download a dataset you will get three files , but we are going to work only with “car data.csv” file.
The columns in the given “car data.csv” file dataset are as follows:
- Car_Name: This column should be filled with the name of the car.
- Year: This column should be filled with the year in which the car was bought.
- Selling_Price: This column should be filled with the price the owner wants to sell the car at.
- Present_Price: This is the current ex-showroom price of the car.
- Kms_Driven:This is the distance completed by the car in km.
- Fuel_Type:Fuel type of the car.
- Seller_Type: Defines whether the seller is a dealer or an individual.
- Transmission: Defines whether the car is manual or automatic.
- Owner: Defines the number of owners the car has previously had.
Here is a sample dataset:

so we will have 2 folders one is the input source which contain a couple of csv files that contain subset of original file “car data.csv”, and other folder will be the input streaming source as emulation for apache spark.
to make it easy for you, run the following script to create our working space from within your terminal:
mkdir data
cd data
mkdir vehicle
cd vehicle
wget "https://github.com/ayaditahar/spark/blob/main/data/vehicle/car data.csv"
mkdir inputStream
cd inputStream
wget https://github.com/ayaditahar/spark/blob/main/data/vehicle/inputStream/car1.csv
wget https://github.com/ayaditahar/spark/blob/main/data/vehicle/inputStream/car2.csv
wget https://github.com/ayaditahar/spark/blob/main/data/vehicle/inputStream/car3.csv
wget https://github.com/ayaditahar/spark/blob/main/data/vehicle/inputStream/car4.csv
wget https://github.com/ayaditahar/spark/blob/main/data/vehicle/inputStream/car5.csv
wget https://github.com/ayaditahar/spark/blob/main/data/vehicle/inputStream/car6.csv
wget https://github.com/ayaditahar/spark/blob/main/data/vehicle/inputStream/car7.csv
mkdir cars
here is the screenshot of first folder(data/vehicle/inputStream) where I created 7 small files, each one contain 10 rows , except for car6.csv contain 50 rows, car7.csv contain 202 rows:
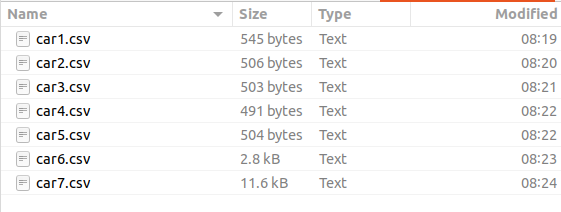
in the second folder, we will constantly upload or copy 1 csv file as demonstration of streaming from previous folder, and spark monitor and read data from that folder:
so we are going to use Pyspark shell with spark version 3.3.0 through our demonstration, but you can use any variant of spark, and it would be the same concept.
Launch pyspark shell:
pyspark
Python 3.9.12 (main, Apr 5 2022, 06:56:58)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.3.0
/_/
Using Python version 3.9.12 (main, Apr 5 2022 06:56:58)
Spark context Web UI available at http://192.168.15.20:4040
Spark context available as 'sc' (master = local[*], app id = local-1665387419073).
SparkSession available as 'spark'.
>>>
so your workspace will be something similar to that:
Define schema
now, the first thing we have to do is to explicitly define the schema layout of our cars dataset, because that is a requirement in spark streaming in order to ensure that the data will be consistent through the streaming process.
So, here is the schema of cars dataset:
from pyspark.sql.types import StructType, StructField, IntegerType, StringType, FloatType, DateType
schema = StructType([
... StructField("Car_Name", StringType(), False),
... StructField("Year", DateType(), False),
... StructField("Selling_Price", FloatType(), False),
... StructField("Present_Price", FloatType(), False),
... StructField("Kms_Driven", IntegerType(), False),
... StructField("Fuel_Type", StringType(), False),
... StructField("Seller_Type", StringType(), False),
... StructField("Transmission", StringType(), False),
... StructField("Owner", IntegerType(), False)
... ])
1. Create batch dataframe
in normal cases where you analyze batch data, here how you define the dataframe:
path = "file:///data/vehicle/car data.csv"
car_data = spark.read.format("csv") \
... .option("header", True) \
... .schema(schema) \
... .load(path)
N.B: when using local data in spark shell, you have to add file:// before the path of that data, otherwise spark assume that path is HDFS by default.
car_data.count()
301
car_data.show(2)
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|Car_Name| Year|Selling_Price|Present_Price|Kms_Driven|Fuel_Type|Seller_Type|Transmission|Owner|
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
| ritz|2014-01-01| 3.35| 5.59| 27000| Petrol| Dealer| Manual| 0|
| sx4|2013-01-01| 4.75| 9.54| 43000| Diesel| Dealer| Manual| 0|
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
only showing top 2 rows
car_data.isStreaming
False
It’s clear from the last result, that the previous dataframe is not a streaming one. Let’s move on and see how to make it streaming.
2. Create the Streaming Dataframe
it should not surprise that is the same way when you want to define streaming dataframe, just replace read with readStream, and you will be good to go as follows:
stream_path = "file:///data/vehicle/inputStream/cars"
car_data_stream = spark.readStream \
... .format("csv") \
... .option("header", True) \
... .schema(schema) \
... .load(stream_path)
car_data_stream.printSchema()
root
|-- Car_Name: string (nullable = true)
|-- Year: date (nullable = true)
|-- Selling_Price: float (nullable = true)
|-- Present_Price: float (nullable = true)
|-- Kms_Driven: integer (nullable = true)
|-- Fuel_Type: string (nullable = true)
|-- Seller_Type: string (nullable = true)
|-- Transmission: string (nullable = true)
|-- Owner: integer (nullable = true)
we can verify if the car data streaming is really streaming and not batch one:
car_data_stream.isStreaming
True
to start spark streaming you have to write the output to something like kafka topic or console to show flow of data in realtime, in our case let’s make simple and output to console:
now keep this pyspark-shell open and copy car1.csv file into inputStream/cars folder, and no surprise, spark will show the 10 rows in car1.csv, at pyspark console:
-------------------------------------------
Batch: 0
-------------------------------------------
+-------------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|Car_Name |Year |Selling_Price|Present_Price|Kms_Driven|Fuel_Type|Seller_Type|Transmission|Owner|
+-------------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|ritz |2014-01-01|3.35 |5.59 |27000 |Petrol |Dealer |Manual |0 |
|sx4 |2013-01-01|4.75 |9.54 |43000 |Diesel |Dealer |Manual |0 |
|ciaz |2017-01-01|7.25 |9.85 |6900 |Petrol |Dealer |Manual |0 |
|wagon r |2011-01-01|2.85 |4.15 |5200 |Petrol |Dealer |Manual |0 |
|swift |2014-01-01|4.6 |6.87 |42450 |Diesel |Dealer |Manual |0 |
|vitara brezza|2018-01-01|9.25 |9.83 |2071 |Diesel |Dealer |Manual |0 |
|ciaz |2015-01-01|6.75 |8.12 |18796 |Petrol |Dealer |Manual |0 |
|s cross |2015-01-01|6.5 |8.61 |33429 |Diesel |Dealer |Manual |0 |
|ciaz |2016-01-01|8.75 |8.89 |20273 |Diesel |Dealer |Manual |0 |
+-------------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
Because we are using append mode (which is the default mode) ,it is guaranteed that each row will be output only once .
So if you now copy the car2.csv file, the 10 rows included in that file will be showed in batch 1:
-------------------------------------------
Batch: 1
-------------------------------------------
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|Car_Name|Year |Selling_Price|Present_Price|Kms_Driven|Fuel_Type|Seller_Type|Transmission|Owner|
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|ciaz |2015-01-01|7.45 |8.92 |42367 |Diesel |Dealer |Manual |0 |
|alto 800|2017-01-01|2.85 |3.6 |2135 |Petrol |Dealer |Manual |0 |
|ciaz |2015-01-01|6.85 |10.38 |51000 |Diesel |Dealer |Manual |0 |
|ciaz |2015-01-01|7.5 |9.94 |15000 |Petrol |Dealer |Automatic |0 |
|ertiga |2015-01-01|6.1 |7.71 |26000 |Petrol |Dealer |Manual |0 |
|dzire |2009-01-01|2.25 |7.21 |77427 |Petrol |Dealer |Manual |0 |
|ertiga |2016-01-01|7.75 |10.79 |43000 |Diesel |Dealer |Manual |0 |
|ertiga |2015-01-01|7.25 |10.79 |41678 |Diesel |Dealer |Manual |0 |
|ertiga |2016-01-01|7.75 |10.79 |43000 |Diesel |Dealer |Manual |0 |
|wagon r |2015-01-01|3.25 |5.09 |35500 |CNG |Dealer |Manual |0 |
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
only the new rows added to the Result Table since the last trigger will be outputted to the console, and you can continue doing that as you like, but let’s do some useful queries that make sense.
Only few queries supported in append mode like: select, where, map, flatMap, filter, join, etc.
Lets see an example:
first press Enter button (or ctrl+c ) to hide the previous query (it still working in the background ), then let’s find the price difference and display it in a new column:
here is the output get append all the 20 rows from car1.csv and car2.csv :
-------------------------------------------
Batch: 0
-------------------------------------------
+-------------+-------------+-------------+----------------+
|Car_Name |Selling_Price|Present_Price|Price_difference|
+-------------+-------------+-------------+----------------+
|ciaz |7.45 |8.92 |1.4700003 |
|alto 800 |2.85 |3.6 |0.75 |
|ciaz |6.85 |10.38 |3.5300002 |
|ciaz |7.5 |9.94 |2.4399996 |
|ertiga |6.1 |7.71 |1.6100001 |
|dzire |2.25 |7.21 |4.96 |
|ertiga |7.75 |10.79 |3.04 |
|ertiga |7.25 |10.79 |3.54 |
|ertiga |7.75 |10.79 |3.04 |
|wagon r |3.25 |5.09 |1.8400002 |
|ritz |3.35 |5.59 |2.2400002 |
|sx4 |4.75 |9.54 |4.79 |
|ciaz |7.25 |9.85 |2.6000004 |
|wagon r |2.85 |4.15 |1.3000002 |
|swift |4.6 |6.87 |2.27 |
|vitara brezza|9.25 |9.83 |0.5799999 |
|ciaz |6.75 |8.12 |1.3699999 |
|s cross |6.5 |8.61 |2.1099997 |
|ciaz |8.75 |8.89 |0.14000034 |
+-------------+-------------+-------------+----------------+
if we add car3.csv what will happen is spark will output the results rows from only that file and not include the previous one (append mode show rows only once ), and here is the output:
-------------------------------------------
Batch: 2
-------------------------------------------
-------------------------------------------
Batch: 1
-------------------------------------------
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|Car_Name|Year |Selling_Price|Present_Price|Kms_Driven|Fuel_Type|Seller_Type|Transmission|Owner|
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|sx4 |2010-01-01|2.65 |7.98 |41442 |Petrol |Dealer |Manual |0 |
|alto k10|2016-01-01|2.85 |3.95 |25000 |Petrol |Dealer |Manual |0 |
|ignis |2017-01-01|4.9 |5.71 |2400 |Petrol |Dealer |Manual |0 |
|sx4 |2011-01-01|4.4 |8.01 |50000 |Petrol |Dealer |Automatic |0 |
|alto k10|2014-01-01|2.5 |3.46 |45280 |Petrol |Dealer |Manual |0 |
|wagon r |2013-01-01|2.9 |4.41 |56879 |Petrol |Dealer |Manual |0 |
|swift |2011-01-01|3.0 |4.99 |20000 |Petrol |Dealer |Manual |0 |
|swift |2013-01-01|4.15 |5.87 |55138 |Petrol |Dealer |Manual |0 |
|swift |2017-01-01|6.0 |6.49 |16200 |Petrol |Individual |Manual |0 |
|alto k10|2010-01-01|1.95 |3.95 |44542 |Petrol |Dealer |Manual |0 |
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
+--------+-------------+-------------+----------------+
|Car_Name|Selling_Price|Present_Price|Price_difference|
+--------+-------------+-------------+----------------+
|sx4 |2.65 |7.98 |5.33 |
|alto k10|2.85 |3.95 |1.1000001 |
|ignis |4.9 |5.71 |0.80999994 |
|sx4 |4.4 |8.01 |3.6100001 |
|alto k10|2.5 |3.46 |0.96000004 |
|wagon r |2.9 |4.41 |1.5099998 |
|swift |3.0 |4.99 |1.9899998 |
|swift |4.15 |5.87 |1.7199998 |
|swift |6.0 |6.49 |0.48999977 |
|alto k10|1.95 |3.95 |2.0 |
+--------+-------------+-------------+----------------+
and sure you can do more filtering options if you want to, let’s filter cars between 2013 and 2019
has manual transmission and Diesel Fuel Type, press Enter and paste the following code:
and here is the output:
-------------------------------------------
Batch: 0
-------------------------------------------
+----------+-------------+----------+-------------+
|Year |Car_Name |Kms_Driven|Present_Price|
+----------+-------------+----------+-------------+
|2015-01-01|ciaz |42367 |8.92 |
|2013-01-01|sx4 |43000 |9.54 |
|2014-01-01|swift |42450 |6.87 |
|2018-01-01|vitara brezza|2071 |9.83 |
|2015-01-01|s cross |33429 |8.61 |
|2016-01-01|ciaz |20273 |8.89 |
+----------+-------------+----------+-------------+
now let’s copy another file car4.csv into InputStream:
>>> -------------------------------------------
Batch: 3
-------------------------------------------
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|Car_Name|Year |Selling_Price|Present_Price|Kms_Driven|Fuel_Type|Seller_Type|Transmission|Owner|
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|ciaz |2015-01-01|7.45 |10.38 |45000 |Diesel |Dealer |Manual |0 |
|ritz |2012-01-01|3.1 |5.98 |51439 |Diesel |Dealer |Manual |0 |
|ritz |2011-01-01|2.35 |4.89 |54200 |Petrol |Dealer |Manual |0 |
|swift |2014-01-01|4.95 |7.49 |39000 |Diesel |Dealer |Manual |0 |
|ertiga |2014-01-01|6.0 |9.95 |45000 |Diesel |Dealer |Manual |0 |
|dzire |2014-01-01|5.5 |8.06 |45000 |Diesel |Dealer |Manual |0 |
|sx4 |2011-01-01|2.95 |7.74 |49998 |CNG |Dealer |Manual |0 |
|dzire |2015-01-01|4.65 |7.2 |48767 |Petrol |Dealer |Manual |0 |
|800 |2003-01-01|0.35 |2.28 |127000 |Petrol |Individual |Manual |0 |
|alto k10|2016-01-01|3.0 |3.76 |10079 |Petrol |Dealer |Manual |0 |
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
-------------------------------------------
Batch: 2
-------------------------------------------
+--------+-------------+-------------+----------------+
|Car_Name|Selling_Price|Present_Price|Price_difference|
+--------+-------------+-------------+----------------+
|ciaz |7.45 |10.38 |2.9300003 |
|ritz |3.1 |5.98 |2.88 |
|ritz |2.35 |4.89 |2.54 |
|swift |4.95 |7.49 |2.54 |
|ertiga |6.0 |9.95 |3.9499998 |
|dzire |5.5 |8.06 |2.5600004 |
|sx4 |2.95 |7.74 |4.79 |
|dzire |4.65 |7.2 |2.5499997 |
|800 |0.35 |2.28 |1.93 |
|alto k10|3.0 |3.76 |0.76 |
+--------+-------------+-------------+----------------+
-------------------------------------------
Batch: 1
-------------------------------------------
+----------+--------+----------+-------------+
|Year |Car_Name|Kms_Driven|Present_Price|
+----------+--------+----------+-------------+
|2014-01-01|swift |39000 |7.49 |
|2014-01-01|ertiga |45000 |9.95 |
|2014-01-01|dzire |45000 |8.06 |
+----------+--------+----------+-------------+
as you can see, 3 (three) batches gets generated for each query we have, and only include data from car4.csv file.
Run Spark SQL in Streaming data
sure we can execute spark SQL queries over streaming data. in order to do that we have to use memory sink instead of console we used above. In memory sink, the output is stored in memory as an in-memory table.
Basically the next streaming query will be triggered every 15 seconds to see if new records' comes in to be shown, otherwise nothing will be shown, and the queryName is what we will use run SQL queries over filtered cars:
we can execute SQL using the queryName we specified above:
spark.sql("select Car_Name, count(*) from cars_flitered group by Car_Name").show()
+-------------+--------+
| Car_Name|count(1)|
+-------------+--------+
| ciaz| 2|
| swift| 2|
| ertiga| 1|
| dzire| 1|
| sx4| 1|
| s cross| 1|
|vitara brezza| 1|
+-------------+--------+
now, once we copy the car5.csv file into inputStream folder, the 3 earlier streams we defined get new data, but the one with spark.sql did not:
-------------------------------------------
Batch: 4
-------------------------------------------
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|Car_Name|Year |Selling_Price|Present_Price|Kms_Driven|Fuel_Type|Seller_Type|Transmission|Owner|
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|sx4 |2003-01-01|2.25 |7.98 |62000 |Petrol |Dealer |Manual |0 |
|baleno |2016-01-01|5.85 |7.87 |24524 |Petrol |Dealer |Automatic |0 |
|alto k10|2014-01-01|2.55 |3.98 |46706 |Petrol |Dealer |Manual |0 |
|sx4 |2008-01-01|1.95 |7.15 |58000 |Petrol |Dealer |Manual |0 |
|dzire |2014-01-01|5.5 |8.06 |45780 |Diesel |Dealer |Manual |0 |
|omni |2012-01-01|1.25 |2.69 |50000 |Petrol |Dealer |Manual |0 |
|ciaz |2014-01-01|7.5 |12.04 |15000 |Petrol |Dealer |Automatic |0 |
|ritz |2013-01-01|2.65 |4.89 |64532 |Petrol |Dealer |Manual |0 |
|wagon r |2006-01-01|1.05 |4.15 |65000 |Petrol |Dealer |Manual |0 |
|ertiga |2015-01-01|5.8 |7.71 |25870 |Petrol |Dealer |Manual |0 |
+--------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
-------------------------------------------
Batch: 2
-------------------------------------------
+----------+--------+----------+-------------+
|Year |Car_Name|Kms_Driven|Present_Price|
+----------+--------+----------+-------------+
|2014-01-01|dzire |45780 |8.06 |
+----------+--------+----------+-------------+
-------------------------------------------
Batch: 3
-------------------------------------------
+--------+-------------+-------------+----------------+
|Car_Name|Selling_Price|Present_Price|Price_difference|
+--------+-------------+-------------+----------------+
|sx4 |2.25 |7.98 |5.73 |
|baleno |5.85 |7.87 |2.02 |
|alto k10|2.55 |3.98 |1.4300001 |
|sx4 |1.95 |7.15 |5.2 |
|dzire |5.5 |8.06 |2.5600004 |
|omni |1.25 |2.69 |1.44 |
|ciaz |7.5 |12.04 |4.54 |
|ritz |2.65 |4.89 |2.2399998 |
|wagon r |1.05 |4.15 |3.1000001 |
|ertiga |5.8 |7.71 |1.9099998 |
+--------+-------------+-------------+----------------+
So, we have to run the query again :
spark.sql("select Car_Name, count(*) from cars_flitered group by Car_Name").show()
+-------------+--------+
| Car_Name|count(1)|
+-------------+--------+
| ciaz| 2|
| swift| 2|
| ertiga| 1|
| dzire| 2|
| sx4| 1|
|vitara brezza| 1|
| s cross| 1|
+-------------+--------+
as we can see the query gets updated with new data (dzire is 2 now) .
Now again copy the car6.csv file which contain 50 rows and run query again, the result is shown next:
-------------------------------------------
Batch: 3
-------------------------------------------
+----------+-----------+----------+-------------+
|Year |Car_Name |Kms_Driven|Present_Price|
+----------+-----------+----------+-------------+
|2014-01-01|etios liva |45000 |6.95 |
|2014-01-01|etios liva |71000 |6.76 |
|2014-01-01|etios cross|83000 |8.93 |
|2015-01-01|etios gd |40000 |7.85 |
+----------+-----------+----------+-------------+
-------------------------------------------
Batch: 5
-------------------------------------------
-------------------------------------------
Batch: 4
-------------------------------------------
+-------------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|Car_Name |Year |Selling_Price|Present_Price|Kms_Driven|Fuel_Type|Seller_Type|Transmission|Owner|
+-------------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|ciaz |2017-01-01|7.75 |9.29 |37000 |Petrol |Dealer |Automatic |0 |
|fortuner |2012-01-01|14.9 |30.61 |104707 |Diesel |Dealer |Automatic |0 |
|fortuner |2015-01-01|23.0 |30.61 |40000 |Diesel |Dealer |Automatic |0 |
|innova |2017-01-01|18.0 |19.77 |15000 |Diesel |Dealer |Automatic |0 |
|fortuner |2013-01-01|16.0 |30.61 |135000 |Diesel |Individual |Automatic |0 |
|innova |2005-01-01|2.75 |10.21 |90000 |Petrol |Individual |Manual |0 |
|corolla altis|2009-01-01|3.6 |15.04 |70000 |Petrol |Dealer |Automatic |0 |
|etios cross |2015-01-01|4.5 |7.27 |40534 |Petrol |Dealer |Manual |0 |
|corolla altis|2010-01-01|4.75 |18.54 |50000 |Petrol |Dealer |Manual |0 |
|etios g |2014-01-01|4.1 |6.8 |39485 |Petrol |Dealer |Manual |1 |
|fortuner |2014-01-01|19.99 |35.96 |41000 |Diesel |Dealer |Automatic |0 |
|corolla altis|2013-01-01|6.95 |18.61 |40001 |Petrol |Dealer |Manual |0 |
|etios cross |2015-01-01|4.5 |7.7 |40588 |Petrol |Dealer |Manual |0 |
|fortuner |2014-01-01|18.75 |35.96 |78000 |Diesel |Dealer |Automatic |0 |
|fortuner |2015-01-01|23.5 |35.96 |47000 |Diesel |Dealer |Automatic |0 |
|fortuner |2017-01-01|33.0 |36.23 |6000 |Diesel |Dealer |Automatic |0 |
|etios liva |2014-01-01|4.75 |6.95 |45000 |Diesel |Dealer |Manual |0 |
|innova |2017-01-01|19.75 |23.15 |11000 |Petrol |Dealer |Automatic |0 |
|fortuner |2010-01-01|9.25 |20.45 |59000 |Diesel |Dealer |Manual |0 |
|corolla altis|2011-01-01|4.35 |13.74 |88000 |Petrol |Dealer |Manual |0 |
+-------------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
only showing top 20 rows
+-------------+-------------+-------------+----------------+
|Car_Name |Selling_Price|Present_Price|Price_difference|
+-------------+-------------+-------------+----------------+
|ciaz |7.75 |9.29 |1.54 |
|fortuner |14.9 |30.61 |15.710001 |
|fortuner |23.0 |30.61 |7.6100006 |
|innova |18.0 |19.77 |1.7700005 |
|fortuner |16.0 |30.61 |14.610001 |
|innova |2.75 |10.21 |7.46 |
|corolla altis|3.6 |15.04 |11.440001 |
|etios cross |4.5 |7.27 |2.77 |
|corolla altis|4.75 |18.54 |13.790001 |
|etios g |4.1 |6.8 |2.7000003 |
|fortuner |19.99 |35.96 |15.969999 |
|corolla altis|6.95 |18.61 |11.660001 |
|etios cross |4.5 |7.7 |3.1999998 |
|fortuner |18.75 |35.96 |17.21 |
|fortuner |23.5 |35.96 |12.459999 |
|fortuner |33.0 |36.23 |3.2299995 |
|etios liva |4.75 |6.95 |2.1999998 |
|innova |19.75 |23.15 |3.3999996 |
|fortuner |9.25 |20.45 |11.200001 |
|corolla altis|4.35 |13.74 |9.389999 |
+-------------+-------------+-------------+----------------+
only showing top 20 rows
spark.sql("select Car_Name, count(*) from cars_flitered group by Car_Name").show()
+-------------+--------+
| Car_Name|count(1)|
+-------------+--------+
| ertiga| 1|
| ciaz| 2|
| swift| 2|
| dzire| 2|
| sx4| 1|
|vitara brezza| 1|
| s cross| 1|
| etios cross| 1|
| etios gd| 1|
| etios liva| 2|
+-------------+--------+
We can also use trigger once, where the query only getting result only from the first time, we can do that by specifying trigger equal to once , and we change the query name:
spark.sql("select Car_Name, avg(Present_Price) from cars_filtered_once group by Car_Name").show()
+-------------+------------------+
| Car_Name|avg(Present_Price)|
+-------------+------------------+
| etios cross| 8.930000305175781|
| etios liva| 6.855000019073486|
| ciaz| 8.90500020980835|
| dzire| 8.0600004196167|
| etios gd| 7.849999904632568|
| swift| 7.179999828338623|
| ertiga| 9.949999809265137|
| sx4| 9.539999961853027|
| s cross| 8.609999656677246|
|vitara brezza| 9.829999923706055|
+-------------+------------------+
now let’s copy the last file we have in our cars dataset which car7.csv that contain 202 rows :
-------------------------------------------
Batch: 6
-------------------------------------------
-------------------------------------------
Batch: 5
-------------------------------------------
-------------------------------------------
Batch: 4
-------------------------------------------
+-------------------------+-------------+-------------+----------------+
|Car_Name |Selling_Price|Present_Price|Price_difference|
+-------------------------+-------------+-------------+----------------+
|fortuner |9.65 |20.45 |10.800001 |
|Royal Enfield Thunder 500|1.75 |1.9 |0.14999998 |
|UM Renegade Mojave |1.7 |1.82 |0.120000005 |
|KTM RC200 |1.65 |1.78 |0.13 |
|Bajaj Dominar 400 |1.45 |1.6 |0.14999998 |
|Royal Enfield Classic 350|1.35 |1.47 |0.120000005 |
|KTM RC390 |1.35 |2.37 |1.0199999 |
|Hyosung GT250R |1.35 |3.45 |2.1 |
|Royal Enfield Thunder 350|1.25 |1.5 |0.25 |
|Royal Enfield Thunder 350|1.2 |1.5 |0.29999995 |
|Royal Enfield Classic 350|1.2 |1.47 |0.26999998 |
|KTM RC200 |1.2 |1.78 |0.5799999 |
|Royal Enfield Thunder 350|1.15 |1.5 |0.35000002 |
|KTM 390 Duke |1.15 |2.4 |1.2500001 |
|Mahindra Mojo XT300 |1.15 |1.4 |0.25 |
|Royal Enfield Classic 350|1.15 |1.47 |0.32000005 |
|Royal Enfield Classic 350|1.11 |1.47 |0.36 |
|Royal Enfield Classic 350|1.1 |1.47 |0.37 |
|Royal Enfield Thunder 500|1.1 |1.9 |0.79999995 |
|Royal Enfield Classic 350|1.1 |1.47 |0.37 |
+-------------------------+-------------+-------------+----------------+
only showing top 20 rows
+-------------------------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|Car_Name |Year |Selling_Price|Present_Price|Kms_Driven|Fuel_Type|Seller_Type|Transmission|Owner|
+-------------------------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
|fortuner |2010-01-01|9.65 |20.45 |50024 |Diesel |Dealer |Manual |0 |
|Royal Enfield Thunder 500|2016-01-01|1.75 |1.9 |3000 |Petrol |Individual |Manual |0 |
|UM Renegade Mojave |2017-01-01|1.7 |1.82 |1400 |Petrol |Individual |Manual |0 |
|KTM RC200 |2017-01-01|1.65 |1.78 |4000 |Petrol |Individual |Manual |0 |
|Bajaj Dominar 400 |2017-01-01|1.45 |1.6 |1200 |Petrol |Individual |Manual |0 |
|Royal Enfield Classic 350|2017-01-01|1.35 |1.47 |4100 |Petrol |Individual |Manual |0 |
|KTM RC390 |2015-01-01|1.35 |2.37 |21700 |Petrol |Individual |Manual |0 |
|Hyosung GT250R |2014-01-01|1.35 |3.45 |16500 |Petrol |Individual |Manual |1 |
|Royal Enfield Thunder 350|2013-01-01|1.25 |1.5 |15000 |Petrol |Individual |Manual |0 |
|Royal Enfield Thunder 350|2016-01-01|1.2 |1.5 |18000 |Petrol |Individual |Manual |0 |
|Royal Enfield Classic 350|2017-01-01|1.2 |1.47 |11000 |Petrol |Individual |Manual |0 |
|KTM RC200 |2016-01-01|1.2 |1.78 |6000 |Petrol |Individual |Manual |0 |
|Royal Enfield Thunder 350|2016-01-01|1.15 |1.5 |8700 |Petrol |Individual |Manual |0 |
|KTM 390 Duke |2014-01-01|1.15 |2.4 |7000 |Petrol |Individual |Manual |0 |
|Mahindra Mojo XT300 |2016-01-01|1.15 |1.4 |35000 |Petrol |Individual |Manual |0 |
|Royal Enfield Classic 350|2015-01-01|1.15 |1.47 |17000 |Petrol |Individual |Manual |0 |
|Royal Enfield Classic 350|2015-01-01|1.11 |1.47 |17500 |Petrol |Individual |Manual |0 |
|Royal Enfield Classic 350|2013-01-01|1.1 |1.47 |33000 |Petrol |Individual |Manual |0 |
|Royal Enfield Thunder 500|2015-01-01|1.1 |1.9 |14000 |Petrol |Individual |Manual |0 |
|Royal Enfield Classic 350|2015-01-01|1.1 |1.47 |26000 |Petrol |Individual |Manual |0 |
+-------------------------+----------+-------------+-------------+----------+---------+-----------+------------+-----+
only showing top 20 rows
+----------+---------+----------+-------------+
|Year |Car_Name |Kms_Driven|Present_Price|
+----------+---------+----------+-------------+
|2015-01-01|grand i10|21125 |5.7 |
|2014-01-01|i20 |77632 |7.6 |
|2015-01-01|verna |61381 |9.4 |
|2013-01-01|verna |45000 |9.4 |
|2013-01-01|grand i10|53000 |5.7 |
|2013-01-01|verna |49000 |9.4 |
|2014-01-01|city |48000 |9.9 |
|2016-01-01|city |19434 |9.4 |
+----------+---------+----------+-------------+
as expected the first streaming get’s updated, let’s see about previous sql that its get triggered every 20 seconds and see if it gets updated or not:
spark.sql("select Car_Name, count(*) from cars_flitered group by Car_Name").show()
+-------------+--------+
| Car_Name|count(1)|
+-------------+--------+
| ertiga| 1|
| ciaz| 2|
| dzire| 2|
| sx4| 1|
| swift| 2|
| s cross| 1|
|vitara brezza| 1|
| etios liva| 2|
| etios cross| 1|
| i20| 1|
| etios gd| 1|
| grand i10| 2|
| city| 2|
| verna| 3|
+-------------+--------+
if we compare it to last run of the same query it gets update for sure.
Now let’s run the last query that use trigger once:
spark.sql("select Car_Name, avg(Present_Price) from cars_filtered_once group by Car_Name").show()
+-------------+------------------+
| Car_Name|avg(Present_Price)|
+-------------+------------------+
| etios cross| 8.930000305175781|
| etios liva| 6.855000019073486|
| ciaz| 8.90500020980835|
| dzire| 8.0600004196167|
| etios gd| 7.849999904632568|
| swift| 7.179999828338623|
| ertiga| 9.949999809265137|
| sx4| 9.539999961853027|
| s cross| 8.609999656677246|
|vitara brezza| 9.829999923706055|
+-------------+------------------+
if you compare this result with the previous one of the same query , it is the same and didn’t get updated and that is the purpose of trigger once, which to get insight of data only one time without the need of updates, which can be useful in some use cases .
Conclusion
as we come to end of our demo, we have seen how to implement streaming analysis over csv files using spark structured streaming which is pretty close on how it is in real world.