How to perform broadcast joins in Spark ?
Publish Date: 2022-07-29
in this article we will see how to perform broadcast join , which known in other names as map side or replicated join, using Apache Spark . If we don’t use a broadcast feature when performing a join on 2 dataframes, it will result in heavy shuffle operations in the cluster, which will make our analysis more expensive in terms of time and resources, and we need to avoid that behavior whenever possible .
Stock Market Dataset
This dataset contains Historical daily prices for all tickers currently trading on NASDAQ. The historic data is retrieved from Yahoo finance and it is publicly available here at kaggle
All that ticker data is then stored in either ETFs or stocks folder, depending on a type. but for our case we will only use stocks folder and not ETFs. Moreover, each filename is the corresponding ticker symbol which is saved in CSV format with common fields:
- symbol: the ticker name
- Date- specifies trading date
- Open - opening price
- High - maximum price during the day
- Low - minimum price during the day
- Close - close price adjusted for splits
- Adj Close - adjusted close price adjusted for both dividends and splits.
- Volume - the number of shares that changed hands during a given day
the symbols_valid_meta.csv contains some additional metadata for each ticker such as full name.
Basically in our case we will join the dataframe created from stocks folder with the dataframe created from symbols_valid_meta.csv to get the symbol with its full name and other infos.
I made some light modifications on stocks' dataset folder, which I remove the header and add a symbol column on each ticker , in order to use it later for joining .
To get hands on practice with the examples below, you will find the dataset available in my GitHub repository .
1. Create a stocks dataframe
after you download the dataset, you can load the stocks' data into spark using Pyspark (we are using pyspark version 3.2 here) with the next following commands.
as our dataset doesn't include header, and it is very large, we have to explicitly specify schema :
>>> stocks_schema = """
symbol string,
Date date,
Open Double,
High Double,
Low Double,
Close Double,
Adj_Close Double,
Volume Double
"""
we can create the dataframe from stocks folder using this syntax:
>>> stocks = spark.read.csv("data/stocks/*.csv",
schema=stocks_schema,
header=False)
the schema should be as the on specified earlier:
>>> stocks.printSchema()
root
|-- symbol: string (nullable = true)
|-- Date: date (nullable = true)
|-- Open: double (nullable = true)
|-- High: double (nullable = true)
|-- Low: double (nullable = true)
|-- Close: double (nullable = true)
|-- Adj_Close: double (nullable = true)
the full stocks folder is of 2.4GB in , and it contains 24 million rows:
>>> stocks.count()
24197442
we can list 5 rows from the dataset to get an overview:
>>> stocks.show(5)
+------+----------+------------------+------------------+------------------+------------------+------------------+-------+
|symbol| Date| Open| High| Low| Close| Adj_Close| Volume|
+------+----------+------------------+------------------+------------------+------------------+------------------+-------+
| HPQ|1962-01-02|0.1312727034091949|0.1312727034091949|0.1241768822073936|0.1241768822073936|0.0068872850388288|2480300|
| HPQ|1962-01-03|0.1241768822073936|0.1241768822073936|0.1215159520506858|0.1228464171290397| 0.006813489831984| 507300|
| HPQ|1962-01-04|0.1228464171290397| 0.126837819814682|0.1179680377244949| 0.120185486972332|0.0066659012809395| 845500|
| HPQ|1962-01-05|0.1197419986128807|0.1197419986128807|0.1175245493650436|0.1175245493650436|0.0065183169208467| 338200|
| HPQ|1962-01-08|0.1175245493650436|0.1192985102534294|0.1153071075677871|0.1192985102534294|0.0066167060285806| 873700|
+------+----------+------------------+------------------+------------------+------------------+------------------+-------+
2.create symbols dataframe
the symbols csv file does include a header, and it's relatively small, so no need to specify a schema. we can load the symbols file into spark using the following syntax:
>>> symbols = spark.read.csv("symbols_valid_meta.csv", inferSchema=True, header=True)
we can see the numbers of rows included in the dataframe, which is 8049 rows:
>>> symbols.count()
8049
we can verify that we are correctly load the symbols data:
>>> symbols.show(5)
+------+--------------------+----------------+---------------+---+--------------+----------+----------------+----------+-------------+----------+
|Symbol| Security Name|Listing Exchange|Market Category|ETF|Round Lot Size|Test Issue|Financial Status|CQS Symbol|NASDAQ Symbol|NextShares|
+------+--------------------+----------------+---------------+---+--------------+----------+----------------+----------+-------------+----------+
| A|Agilent Technolog...| N| | N| 100| N| null| A| A| N|
| AA|Alcoa Corporation...| N| | N| 100| N| null| AA| AA| N|
| AAAU|Perth Mint Physic...| P| | Y| 100| N| null| AAAU| AAAU| N|
| AACG|ATA Creativity Gl...| Q| G| N| 100| N| N| null| AACG| N|
| AADR|AdvisorShares Dor...| P| | Y| 100| N| null| AADR| AADR| N|
+------+--------------------+----------------+---------------+---+--------------+----------+----------------+----------+-------------+----------+
only showing top 5 rows
>>> symbols.printSchema()
root
|-- Symbol: string (nullable = true)
|-- Security Name: string (nullable = true)
|-- Listing Exchange: string (nullable = true)
|-- Market Category: string (nullable = true)
|-- ETF: string (nullable = true)
|-- Round Lot Size: string (nullable = true)
|-- Test Issue: string (nullable = true)
|-- Financial Status: string (nullable = true)
|-- CQS Symbol: string (nullable = true)
|-- NASDAQ Symbol: string (nullable = true)
|-- NextShares: string (nullable = true)
from previous output , it is obvious that the stocks dataframe is so much larger than symbols dataframe.
For our case we are looking to get symbol existing in stocks with it’s full name in symbols .
Default join behavior
by default, if you try to perform a join between 2 dataframes, and the second dataframe is less than 10 MB size, then spark will try to perform a broadcast (distribute) to the second Dataframe across all executors. If you want to verify this behavior, you can check the broadcastJoinThreshhold property:
>>> spark.conf.get("spark.sql.autoBroadcastJoinThreshold")
'10485760b'
the returned value is 10485760b bytes, which is equal to 10 MB.
disable broadcast join
Let’s disable that behavior and perform a simple join, between stocks and symbols and watch the behavior :
>>> spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 0)
stocks.join(
symbols, stocks.symbol == symbols.Symbol, "inner").\
select(stocks.symbol, "Security Name").\
distinct().\
show(5,truncate=False)
+------+---------------------------------------------------------------------------------------+
|symbol|Security Name |
+------+---------------------------------------------------------------------------------------+
|AA |Alcoa Corporation Common Stock |
|AACG |ATA Creativity Global - American Depositary Shares, each representing two common shares|
|AAMC |Altisource Asset Management Corp Com |
|AAPL |Apple Inc. - Common Stock |
|AAT |American Assets Trust, Inc. Common Stock |
+------+---------------------------------------------------------------------------------------+
only showing top 5 rows
this join took 49 seconds.
if we see the DAG Visualization for the stages related to this join , it shows the use of sort merge join as the picture shows:
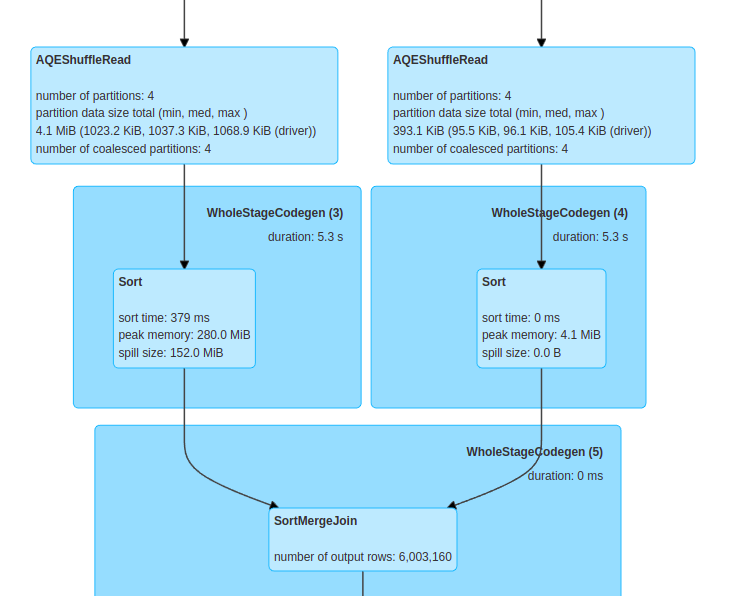
which means it use shuffle of both dataframes, which is not the case in the next step when we perform broadcast join.
Enable broadcast join
The key feature here is to broadcast the smaller dataset to all executors , that makes it available in all nodes rather than left Spark to perform a reduced join by default if the dataset size is larger than 10 MB.
you can change default behavior to larger value , let’s say 1 GB for real cluster to meet the requirement needs in some production environments.:
>>> spark.conf.set('spark.sql.autoBroadcastJoinThreshold', '1073741824b')
But keep in mind , even if you make the Broadcast Join Threshold larger, that does not mean you will always get good results in join operations in spark, it depends also on other factors such number of cores , driver and executors memory, and type of join either it is inner or left or other types.
To keep things simple for our case, let’s reset the autoBroadcastJoinThreshold property to its original value:
>>> spark.conf.set('spark.sql.autoBroadcastJoinThreshold', '10485760b')
we have stocks is huge dataframe, but symbols is a small one , so we will broadcast the smallest dataframe (symbols) and make it available to all executors:
>>> stocks.join(
broadcast(symbols),
stocks.symbol == symbols.Symbol, "inner").\
select(stocks.symbol, "Security Name").\
distinct().\
show()
+------+---------------------------------------------------------------------------------------+
|symbol|Security Name |
+------+---------------------------------------------------------------------------------------+
|AA |Alcoa Corporation Common Stock |
|AACG |ATA Creativity Global - American Depositary Shares, each representing two common shares|
|AAMC |Altisource Asset Management Corp Com |
|AAPL |Apple Inc. - Common Stock |
|AAT |American Assets Trust, Inc. Common Stock |
+------+---------------------------------------------------------------------------------------+
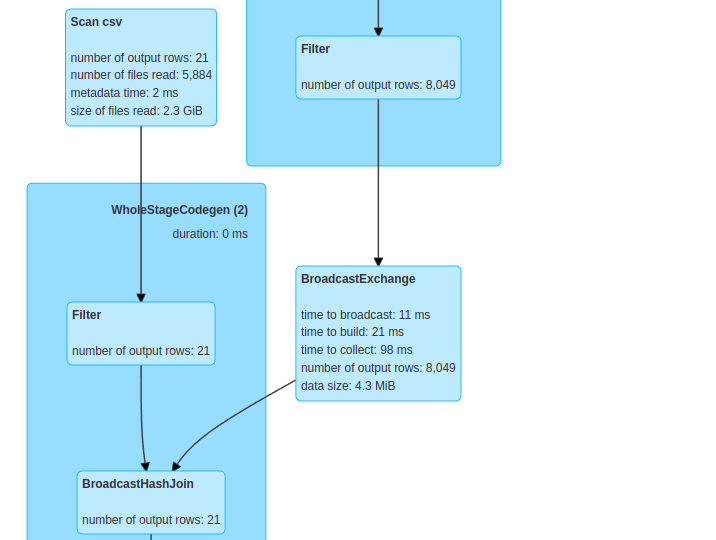
from the dag visualization , we can clearly see the broadcast of symbols dataframe into stocks dataframe:

this join took 39 seconds.
it's clear that the broadcast join take a lower time. it could take about same amount of time or close if the datasets is small, but in most cases broadcast join can make a difference.
final thoughts
after doing our analysis with Pyspark, we can say that broadcast joins is better than reduce join but with some caveats. and it is useful for most cases to use broadcast join for inner join anf left join, and don't forget to always broadcast the smallest dataframe.