Read/Write data from/to PostgreSQL tables using Spark
Publish Date: 2022-10-02
Apache Spark is a fast and general computing engine used for big data processing. It can process data from different sources and formats, one of them is data from relational databases like PostgreSQL.
In our article, we will show you the steps to on how to read data from PostgreSQL tables into Spark for further processing, and write back results into PostgreSQL, along with different steps and configuration required to it.
1. Load the dvd rental sample database
if you already have an existing database, you can skip this steps. For our demo we will use the rental DVD sample database which represents the business processes of a DVD rental store. The DVD rental database has many objects, including:
- 15 tables
- 1 trigger
- 7 views
- 8 functions
- 1 domain
- 13 sequences
It is a good opportunity by the way to learn how to load a database into PostgresSQL if you don't know how before. To load the database into PostgresSQL, you can either use pgAdmin or psql tool. For simplicity, we are going to use pgAdmin on the following steps.
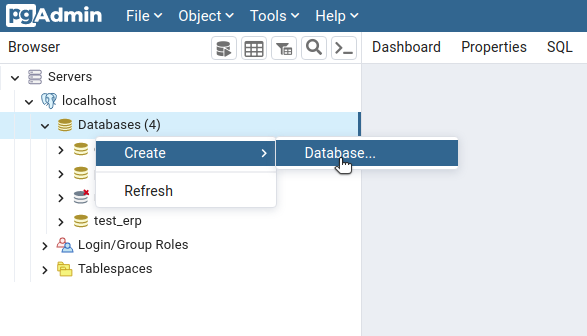
First, launch pgAdmin and connect to the PostgreSQL Server . Right click on databases and choose: create > database from options list:
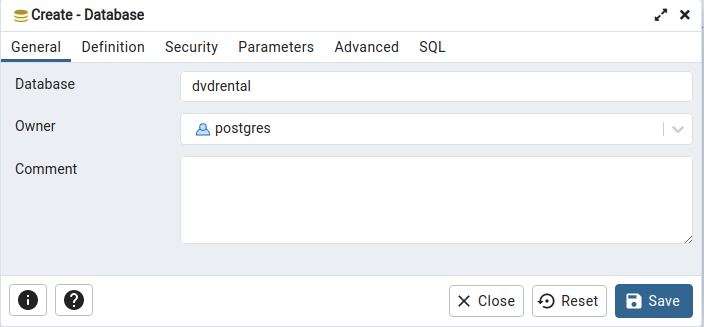
Give it a name as dvdrental and click save:
The newly created database will be listed here:

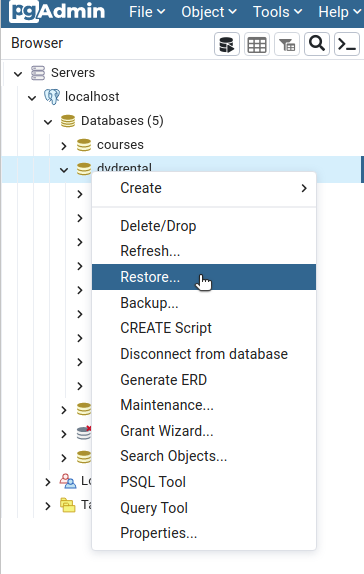
Now, click on the dvdrental database and from options list choose restore:
A windows will appear , in file name choose the location of dvdrental.tar file (it will be in downloads folder by default), and click :

once the restore completes (about 2 seconds), a window like this will be shown:
now click on dvdrental database, under public schema you will find the different tables (you might need to click on tables and choose refresh) and objects ready to be used as shown in the following picture:
after we successfully prepare our sample database , we can go to our next step which is to query data from Spark.
2. Adding required Dependencies
we are going to use Spark 3.3 with Scala option, so there is 2 options in our case: either using spark-shell or working with sbt:
spark-shell
if you prefer working with Spark-Shell then you need to specify path of PostegreSQL jar file
you can find the corresponding version to your installation of postgresql here in mvn repository . you might want to choose an older version for backward compatibility.
In our demo we choose the 42.3.6 version , you can download the jar file: download the jar file and put into jars folder in $SPARK_HOME. or follow these steps to take care of that :
cd $SPARK_HOME
wget https://repo1.maven.org/maven2/org/postgresql/postgresql/42.3.6/postgresql-42.3.6.jar
mv postgresql-42.3.6.jar jars
Now, you can launch Spark Shell by specifying full path, (even without specifying the jar file it will work, because it is already in jars folder), just run the next command:
spark-shell --driver-class-path jars/postgresql-42.3.6.jar --jars jars/postgresql-42.3.6.jar
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://192.168.200.35:4040
Spark context available as 'sc' (master = local[*], app id = local-1659212612005).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.3.0
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 1.8.0_312)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Using SBT dependency
If you are working using an IDE, then append the following line to build.sbt file :
// https://mvnrepository.com/artifact/org.postgresql/postgresql
libraryDependencies += "org.postgresql" % "postgresql" % "42.3.6"
in either cases you choose, the following code will be the same. in our case we are using spark-shell .
3. Connect to Postgres
we need to specify the driver ,url, user, and password in order to use them later(change user and password value to your values):
val driver = "org.postgresql.Driver"
val url = "jdbc:postgresql://localhost:5432/dvdrental"
val user = "postgres"
val password = "postgres"
then we have to create a function which take "table name" as parameter and return a dataframe:
def readTable(tableName: String) = {
| spark.read
| .format("jdbc")
| .option("driver", driver)
| .option("url", url)
| .option("user", user)
| .option("password", password)
| .option("dbtable", s"public.$tableName")
| .load()
|}
the only part left is to choose the table you want to query, let’s say the ‘customer’ table, using the function we just create:
val customerDF = readTable("customer")
you can verify the result of returned data :
customerDF.show()
+-----------+--------+----------+---------+--------------------+----------+----------+-----------+--------------------+------+
|customer_id|store_id|first_name|last_name| email|address_id|activebool|create_date| last_update|active|
+-----------+--------+----------+---------+--------------------+----------+----------+-----------+--------------------+------+
| 524| 1| Jared| Ely|jared.ely@sakilac...| 530| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 1| 1| Mary| Smith|mary.smith@sakila...| 5| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 2| 1| Patricia| Johnson|patricia.johnson@...| 6| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 3| 1| Linda| Williams|linda.williams@sa...| 7| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 4| 2| Barbara| Jones|barbara.jones@sak...| 8| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 5| 1| Elizabeth| Brown|elizabeth.brown@s...| 9| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 6| 2| Jennifer| Davis|jennifer.davis@sa...| 10| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 7| 1| Maria| Miller|maria.miller@saki...| 11| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 8| 2| Susan| Wilson|susan.wilson@saki...| 12| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 9| 2| Margaret| Moore|margaret.moore@sa...| 13| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 10| 1| Dorothy| Taylor|dorothy.taylor@sa...| 14| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 11| 2| Lisa| Anderson|lisa.anderson@sak...| 15| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 12| 1| Nancy| Thomas|nancy.thomas@saki...| 16| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 13| 2| Karen| Jackson|karen.jackson@sak...| 17| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 14| 2| Betty| White|betty.white@sakil...| 18| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 15| 1| Helen| Harris|helen.harris@saki...| 19| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 16| 2| Sandra| Martin|sandra.martin@sak...| 20| true| 2006-02-14|2013-05-26 14:49:...| 0|
| 17| 1| Donna| Thompson|donna.thompson@sa...| 21| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 18| 2| Carol| Garcia|carol.garcia@saki...| 22| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 19| 1| Ruth| Martinez|ruth.martinez@sak...| 23| true| 2006-02-14|2013-05-26 14:49:...| 1|
+-----------+--------+----------+---------+--------------------+----------+----------+-----------+--------------------+------+
only showing top 20 rows
if you prefer to use sql directly, you can as well, first you need to create a temporary view from dataframe:
customerDF.createOrReplaceTempView("customer")
then you can run sql commands as you want:
spark.sql("select * from customer limit 5").show()
+-----------+--------+----------+---------+--------------------+----------+----------+-----------+--------------------+------+
|customer_id|store_id|first_name|last_name| email|address_id|activebool|create_date| last_update|active|
+-----------+--------+----------+---------+--------------------+----------+----------+-----------+--------------------+------+
| 524| 1| Jared| Ely|jared.ely@sakilac...| 530| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 1| 1| Mary| Smith|mary.smith@sakila...| 5| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 2| 1| Patricia| Johnson|patricia.johnson@...| 6| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 3| 1| Linda| Williams|linda.williams@sa...| 7| true| 2006-02-14|2013-05-26 14:49:...| 1|
| 4| 2| Barbara| Jones|barbara.jones@sak...| 8| true| 2006-02-14|2013-05-26 14:49:...| 1|
+-----------+--------+----------+---------+--------------------+----------+----------+-----------+--------------------+------+
spark.sql("select count(*) from customer").show()
+--------+
|count(1)|
+--------+
| 599|
+--------+
that's look obvious, let's make more real world problem and create another dataframe, then do join between them using spark sql.
for the tables in our database case, whenever a customer makes a payment, a new row is inserted into the payment table.
Each customer may have zero or many payments. However, each payment belongs to one and only one customer. The customer_id column establishes the relationship between the two tables.
The following statement uses the INNER JOIN clause to select data from both tables:
SELECT customer.customer_id,first_name,last_name,amount,payment_date
FROM customer
INNER JOIN payment ON payment.customer_id = customer.customer_id
ORDER BY payment_date;
because joins are very expensive in relational databases if the tables are very big and disparate, we will run our query in spark to avoid that. so we have to create a payment dataframe:
val paymentDF = readTable("payment")
paymentDF.show()
+----------+-----------+--------+---------+------+--------------------+
|payment_id|customer_id|staff_id|rental_id|amount| payment_date|
+----------+-----------+--------+---------+------+--------------------+
| 17503| 341| 2| 1520| 7.99|2007-02-15 22:25:...|
| 17504| 341| 1| 1778| 1.99|2007-02-16 17:23:...|
| 17505| 341| 1| 1849| 7.99|2007-02-16 22:41:...|
| 17506| 341| 2| 2829| 2.99|2007-02-19 19:39:...|
| 17507| 341| 2| 3130| 7.99|2007-02-20 17:31:...|
| 17508| 341| 1| 3382| 5.99|2007-02-21 12:33:...|
| 17509| 342| 2| 2190| 5.99|2007-02-17 23:58:...|
| 17510| 342| 1| 2914| 5.99|2007-02-20 02:11:...|
| 17511| 342| 1| 3081| 2.99|2007-02-20 13:57:...|
| 17512| 343| 2| 1547| 4.99|2007-02-16 00:10:...|
| 17513| 343| 1| 1564| 6.99|2007-02-16 01:15:...|
| 17514| 343| 2| 1879| 0.99|2007-02-17 01:26:...|
| 17515| 343| 2| 1922| 0.99|2007-02-17 04:32:...|
| 17516| 343| 2| 2461| 6.99|2007-02-18 18:26:...|
| 17517| 343| 1| 2980| 8.99|2007-02-20 07:03:...|
| 17518| 343| 1| 3407| 0.99|2007-02-21 14:42:...|
| 17519| 344| 1| 1341| 3.99|2007-02-15 10:54:...|
| 17520| 344| 2| 1475| 4.99|2007-02-15 19:36:...|
| 17521| 344| 1| 1731| 0.99|2007-02-16 14:00:...|
| 17522| 345| 2| 1210| 0.99|2007-02-15 01:26:...|
+----------+-----------+--------+---------+------+--------------------+
only showing top 20 rows
then we create a temporary view in order to deal with it directly with sql :
paymentDF.createOrReplaceTempView("payment")
to test some queries:
spark.sql("select * from payment limit 5").show()
+----------+-----------+--------+---------+------+--------------------+
|payment_id|customer_id|staff_id|rental_id|amount| payment_date|
+----------+-----------+--------+---------+------+--------------------+
| 17503| 341| 2| 1520| 7.99|2007-02-15 22:25:...|
| 17504| 341| 1| 1778| 1.99|2007-02-16 17:23:...|
| 17505| 341| 1| 1849| 7.99|2007-02-16 22:41:...|
| 17506| 341| 2| 2829| 2.99|2007-02-19 19:39:...|
| 17507| 341| 2| 3130| 7.99|2007-02-20 17:31:...|
+----------+-----------+--------+---------+------+--------------------+
Now we can run the SqL Join using spark-sql on top of both dataframes:
val joinQuery = spark.sql("""
|SELECT customer.customer_id, first_name, last_name, amount, payment_date
|FROM customer
|INNER JOIN payment
|ON payment.customer_id = customer.customer_id
|ORDER BY payment_date
|limit 5
|""".stripMargin)
the returned result is like that:
joinQuery.show()
+-----------+----------+---------+------+--------------------+
|customer_id|first_name|last_name|amount| payment_date|
+-----------+----------+---------+------+--------------------+
| 416| Jeffery| Pinson| 2.99|2007-02-14 21:21:...|
| 516| Elmer| Noe| 4.99|2007-02-14 21:23:...|
| 239| Minnie| Romero| 4.99|2007-02-14 21:29:...|
| 592| Terrance| Roush| 6.99|2007-02-14 21:41:...|
| 49| Joyce| Edwards| 0.99|2007-02-14 21:44:...|
+-----------+----------+---------+------+--------------------+
we can save the result of our query back to PostgreSQL as well. the next code will create and save the query result in a table named table1 (the table will be created automatically , you can specify one as well):
joinQuery.write.
| format("jdbc").
| option("driver", driver).
| option("url", url).
| option("user", user).
| option("password", password).
| option("dbtable", s"public.table1").
| option("mode", "append").
| save()
you can check in PgAdmin whether the writing was successful (it should be).
Conclusion
after you completed the demo, now you are able to deal with relational databases using Apache Spark without any problem.
if you find any problem leave a comment below.