Implement A* Shortest Path using Neo4j
Publish Date: 2022-10-17

The A* (pronounced "A-Star") Shortest Path algorithm computes the shortest path between two nodes. A* is an informed search algorithm as it uses a heuristic function to guide the graph traversal. The algorithm supports weighted graphs with positive relationship weights.
Today We will learn How to implement the A* Shortest Path Algorithm using real data in Neo4j with Cypher Language.
How It works
If you are not familiar or heard about the famous Dijkstra’s algorithm, then, simply it is an algorithm its purpose is to find the shortest path between 2 nodes, by starting and set a single node as the source and find the shortest path between that node and every other, up to the target; by combining the total lowest. it ‘s been widely used in networks routing protocols such IS-IS and OSPF and also as subroutine in Johnson’s algorithm.
for the A* algorithm it combines the already computed distances with the result of heuristic function . For each iteration from the source, it continues traversing the graph and combine the lowest costs.
I described The principles of Heuristic Function and GPS coordinates and how it works in order to find the distance between two (2) given points in the sphere (earth) using their latitude and longitude, and how to find those geo-coordinates as well.
The A* is still based on the Dijkstra’s shortest path algorithm principle, plus it uses the heuristic function and haversine formula to guide the search and find the smallest distance using geo-coordinates stored on the nodes in the graph.
In order for the heuristic function to perform better, relationships weights (duration, distance) between nodes must represent real measurement , ideally distances in nautical miles . Kilometers or miles also work, but the heuristic works best for nautical miles. As we are dealing with distances in lands and to keep results simple, we will use kilometers, which works as well.
Install Graph Data Science library:
The Neo4j Graph Data Science (GDS) library contains many graph algorithms. The algorithms are divided into categories including centrality and community detection going onward into path finding, Pregel API and others which represent different problem classes.
The Neo4j GDS library includes many path finding algorithms, that find the path between two or more nodes or evaluate the availability and quality of paths. These algorithms grouped by quality tier. And not surprisinly, the A* shortest path algorithm is part of the Path finding algorithms .
So, in order to execute the A* shortest path algorithm, we need to install the GDS plugin.
If you are not familiar with Neo4j and how to get started using Cypher for the initial steps, check out my article entitled Introduction to CRUD Operations in Neo4j with Cypher as we are not repeating the steps here.
once you launch Neo4J Desktop, create a database within a project. Click on your database and on the right side panel, you will find plugins tab, click on it. Then choose Graph Data Science Library and click on the blue install button :
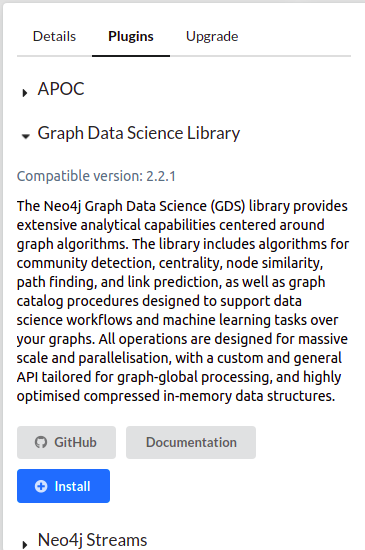
Once the installation complete, you're done with the plugin. now, start the database and launch neo4j browser:
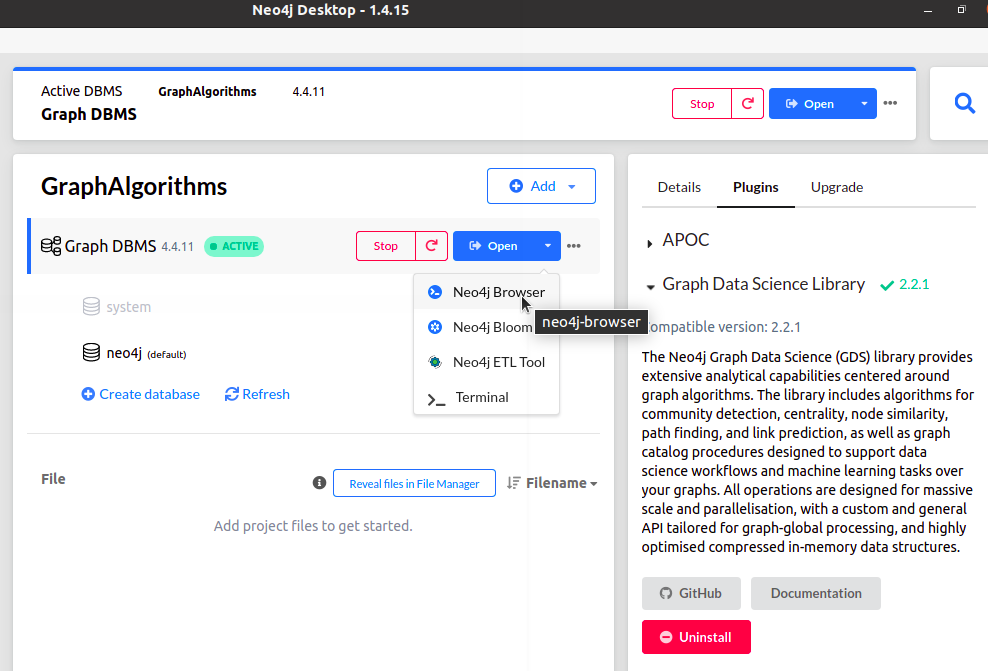
here is neo4j browser, where for the rest of our demo we will execute our Cypher code.
Our dataset:
In our demonstration we will try to find the lowest path between two given cities in Algeria using their real geo-coordinates , and for the graph weight’s we use real distances in kilometers and duration times in hours for approximation of 80 Km/h .

we will use only a subset of the cities and the road links connected between them.
The nodes actually represent cities with it’s name, longitude, and latitude the connections or vertices represent roads between the cities and include the actual distance and average duration to traverse that road from either directions at speed from 70km/h to 90km/h . to create that graph nodes neo4j, run the following cypher code:
CREATE (Algiers:Station {name: 'Algiers',latitude: 36.7530171, longitude: 3.04185570}),
(Annaba:Station {name: 'Annaba',latitude: 36.902859, longitude: 7.755543}),
(Oran:Station {name: 'Oran',latitude: 35.6969444, longitude: -0.6330556}),
(Setif:Station {name: 'Setif',latitude: 36.18898, longitude: 5.414416}),
(Constantine:Station {name: 'Constantine',latitude: 36.35, longitude: 6.6}),
(Tiaret:Station {name: 'Tiaret' ,latitude: 35.3673553, longitude: 1.32203219}),
(Tamanghasset:Station {name: 'Tamanghasset',latitude: 22.7854543, longitude: 5.5324465}),
(Tlemcen:Station {name: 'Tlemcen',latitude: 34.8825, longitude: -1.31393}),
(Tindouf:Station {name: 'Tindouf',latitude: 27.54390695, longitude: -6.24005386528793}),
(Algiers)-[:CONNECTION {distance: 537,duration: 6.7}]->(Annaba),
(Algiers)-[:CONNECTION {distance: 414,duration: 4.6}]->(Oran),
(Setif)-[:CONNECTION {distance: 269,duration: 3.3}]->(Algiers),
(Setif)-[:CONNECTION {distance: 272,duration: 3.6}]->(Annaba),
(Setif)-[:CONNECTION {distance: 125,duration: 1.5}]->(Constantine),
(Constantine)-[:CONNECTION {distance: 149,duration: 2.1}]->(Annaba),
(Constantine)-[:CONNECTION {distance: 168,duration: 2.4}]->(Annaba),
(Tlemcen)-[:CONNECTION {distance: 176,duration: 2.0}]->(Oran),
(Tlemcen)-[:CONNECTION {distance: 332,duration: 4.3}]->(Tiaret),
(Tlemcen)-[:CONNECTION {distance: 356,duration: 4.7}]->(Tiaret),
(Tiaret)-[:CONNECTION {distance: 468,duration: 6.7}]->(Setif),
(Tiaret)-[:CONNECTION {distance: 494,duration: 6.9}]->(Setif),
(Tiaret)-[:CONNECTION {distance: 270,duration: 4.0}]->(Algiers),
(Tiaret)-[:CONNECTION {distance: 232,duration: 3.3}]->(Oran),
(Tamanghasset)-[:CONNECTION {distance: 1939,duration: 28.1}]->(Setif),
(Tamanghasset)-[:CONNECTION {distance: 1801,duration: 26.6}]->(Tiaret),
(Tamanghasset)-[:CONNECTION {distance: 1930,duration: 28.0}]->(Algiers),
(Tindouf)-[:CONNECTION {distance: 1753,duration: 28.7}]->(Tiaret),
(Tindouf)-[:CONNECTION {distance: 1650,duration: 27.1}]->(Tlemcen),
(Tindouf)-[:CONNECTION {distance: 2349,duration: 39.1}]->(Tamanghasset);
Added 9 labels, created 9 nodes, set 67 properties, created 20 relationships, completed after 493 ms.
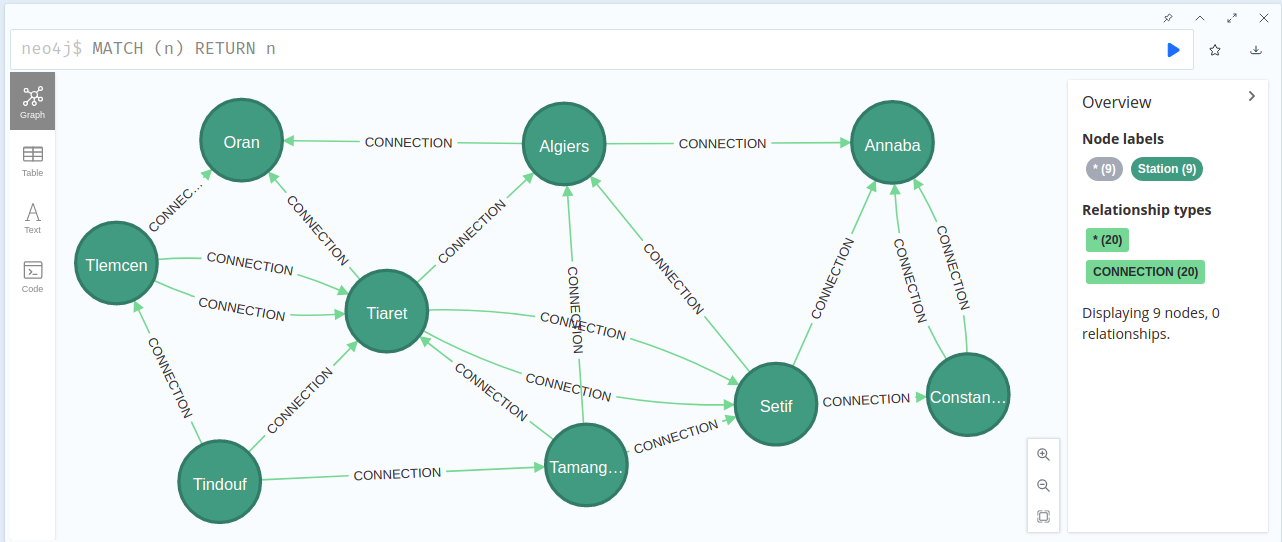
let’s see how our created graph looks like:
MATCH (n) RETURN n
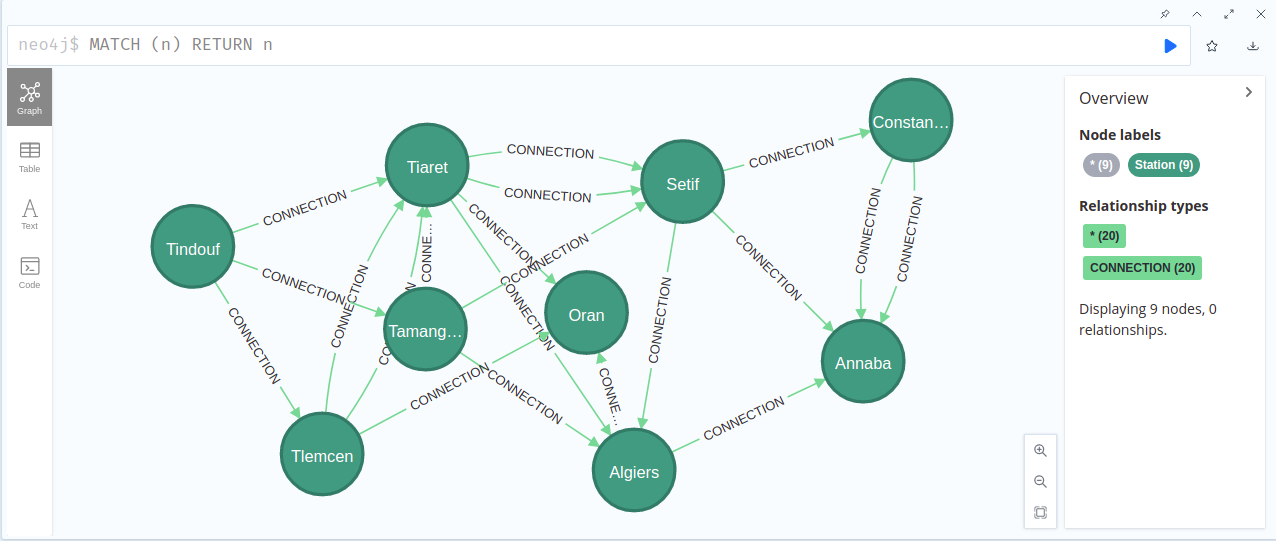
and here is the graph after rearranging the nodes to be more clear:
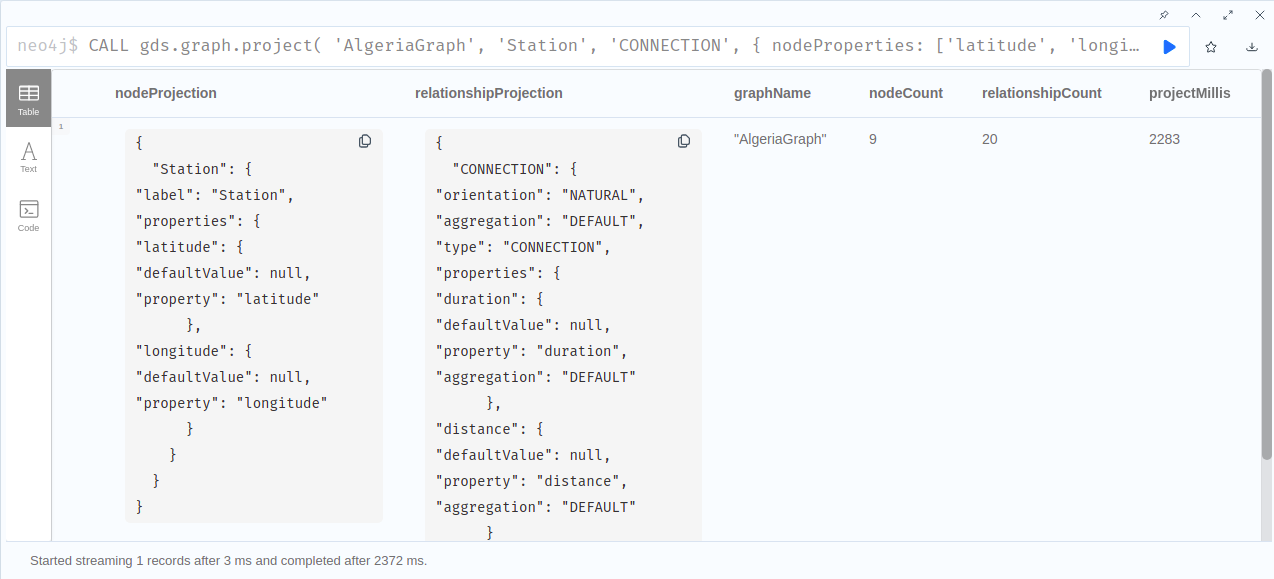
CALL gds.graph.project(
'AlgeriaGraph',
'Station',
'CONNECTION',
{
nodeProperties: ['latitude', 'longitude'],
relationshipProperties: ['distance', 'duration']
}
)
╒══════════════════════════════════════════════════════════════════════╤══════════════════════════════════════════════════════════════════════╤══════════════╤═══════════╤═══════════════════╤═══════════════╕
│"nodeProjection" │"relationshipProjection" │"graphName" │"nodeCount"│"relationshipCount"│"projectMillis"│
╞══════════════════════════════════════════════════════════════════════╪══════════════════════════════════════════════════════════════════════╪══════════════╪═══════════╪═══════════════════╪═══════════════╡
│{"Station":{"label":"Station","properties":{"latitude":{"defaultValue"│{"CONNECTION":{"orientation":"NATURAL","aggregation":"DEFAULT","type":│"AlgeriaGraph"│9 │20 │2283 │
│:null,"property":"latitude"},"longitude":{"defaultValue":null,"propert│"CONNECTION","properties":{"duration":{"defaultValue":null,"property":│ │ │ │ │
│y":"longitude"}}}} │"duration","aggregation":"DEFAULT"},"distance":{"defaultValue":null,"p│ │ │ │ │
│ │roperty":"distance","aggregation":"DEFAULT"}}}} │ │ │ │ │
└──────────────────────────────────────────────────────────────────────┴──────────────────────────────────────────────────────────────────────┴──────────────┴───────────┴───────────────────┴───────────────┘
Syntax of using gds library
generally when you create a graph and give it a name, you can execute your algorithms over it in different available execution modes (stream, stats, mutate, write). Through our demonstration we will use the stream mode as it returns the results directly to screen ,more technically as a stream of records.
You can also estimate how much it takes the algorithm on a graph by appending a command with estimate keyword.
So the general syntax to execute an algorithm would be:
for the tier parameter, it can refer to some algorithms where it is in alpha or beta state.
We will see more on the parameters and configurations shortly.
Implementation of A*
once we have our dataset, and we know the general syntax, and without any further ado, let’s get started.
the query to run an algorithm has 4 main parts:
- match part: to select the source and target nodes
- CALL part: this part where you call the A* shortest path algorithm from GDS library with execution mode and configuration parameters such source and target nodes, longitude and latitude properties.
- YIELD: to specify what values to return in streaming mode
- return: to return the result and terminate the query, and in our case it could the same as YIELD, and in most cases is different.
Let’s say we want to find the shortest path between ‘Tlemcen‘ and ‘Setif’, and as we said earlier the A* algorithm uses the geo-coordinates to find the lowest distance , we need to specify these parameters in the call part.

Let’s first run an estimation of the algorithm in write mode, to understand the memory impact that running the algorithm on our graph will have
MATCH (source:Station {name: 'Tlemcen'}), (target:Station {name: 'Setif'})
CALL gds.shortestPath.astar.write.estimate('AlgeriaGraph', {
sourceNode: source,
targetNode: target,
latitudeProperty: 'latitude',
longitudeProperty: 'longitude',
writeRelationshipType: 'PATH'
})
YIELD nodeCount, relationshipCount, bytesMin, bytesMax, requiredMemory
RETURN nodeCount, relationshipCount, bytesMin, bytesMax, requiredMemory
╒═══════════╤═══════════════════╤══════════╤══════════╤════════════════╕
│"nodeCount"│"relationshipCount"│"bytesMin"│"bytesMax"│"requiredMemory"│
╞═══════════╪═══════════════════╪══════════╪══════════╪════════════════╡
│9 │20 │1496 │1496 │"1496 Bytes" │
└───────────┴───────────────────┴──────────┴──────────┴────────────────┘
If the estimation shows that there is a very high probability of the execution going over its memory limitations, the execution is prohibited, and since our graph is a small one, the algorithm will have no impact as shown above.
Now let’s run the algorithm in stream mode to get our results and find the smallest path between 'Tlemcen' and 'Setif' city :
MATCH (source:Station {name: 'Tlemcen'}), (target:Station {name: 'Setif'})
CALL gds.shortestPath.astar.stream('AlgeriaGraph', {
sourceNode: source,
targetNode: target,
latitudeProperty: 'latitude',
longitudeProperty: 'longitude',
relationshipWeightProperty: 'distance'
})
YIELD index, sourceNode, targetNode, totalCost, nodeIds, costs, path
RETURN
index,
gds.util.asNode(sourceNode).name AS sourceNodeName,
gds.util.asNode(targetNode).name AS targetNodeName,
totalCost,
[nodeId IN nodeIds | gds.util.asNode(nodeId).name] AS nodeNames,
costs,
nodes(path) as path
ORDER BY index
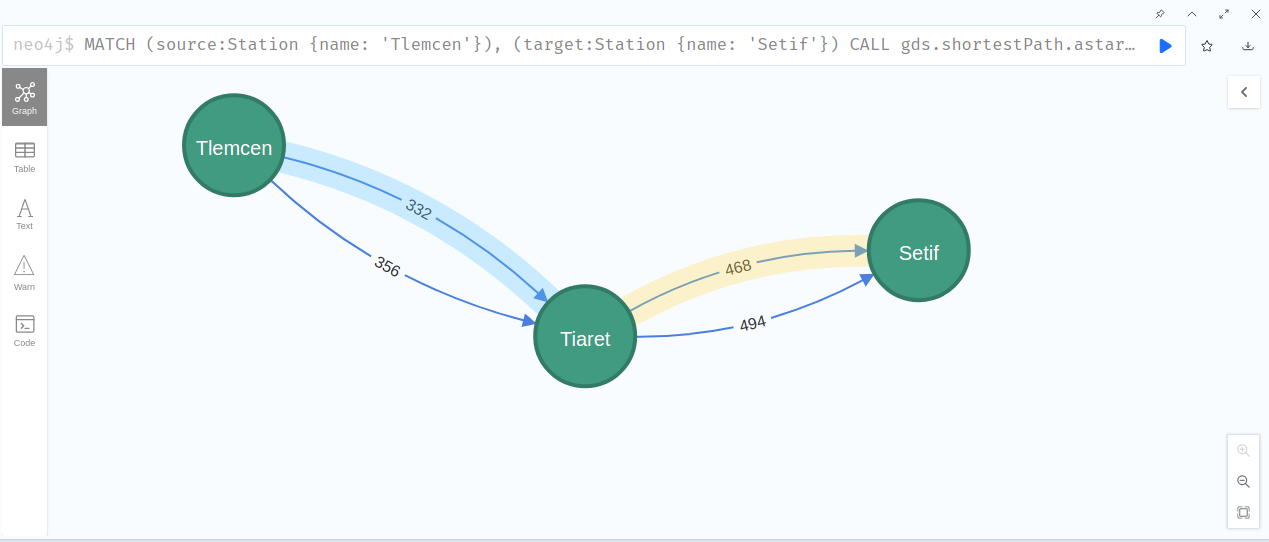
you can verify the path when you look to text result which result in 800 Km distance:
╒═══════╤════════════════╤════════════════╤═══════════╤════════════════════════════╤═════════════════╤══════════════════════════════════════════════════════════════════════╕
│"index"│"sourceNodeName"│"targetNodeName"│"totalCost"│"nodeNames" │"costs" │"path" │
╞═══════╪════════════════╪════════════════╪═══════════╪════════════════════════════╪═════════════════╪══════════════════════════════════════════════════════════════════════╡
│0 │"Tlemcen" │"Setif" │800.0 │["Tlemcen","Tiaret","Setif"]│[0.0,332.0,800.0]│[{"name":"Tlemcen","latitude":34.8825,"longitude":-1.31393},{"name":"T│
│ │ │ │ │ │ │iaret","latitude":35.3673553,"longitude":1.32203219},{"name":"Setif","│
│ │ │ │ │ │ │latitude":36.18898,"longitude":5.414416}] │
└───────┴────────────────┴────────────────┴───────────┴────────────────────────────┴─────────────────┴──────────────────────────────────────────────────────────────────────┘
you can try changing distance into duration, and you will result will be the same:
MATCH (source:Station {name: 'Tlemcen'}), (target:Station {name: 'Setif'})
CALL gds.shortestPath.astar.stream('AlgeriaGraph', {
sourceNode: source,
targetNode: target,
latitudeProperty: 'latitude',
longitudeProperty: 'longitude',
relationshipWeightProperty: 'duration'
})
YIELD index, sourceNode, targetNode, totalCost, nodeIds, costs, path
RETURN
index,
gds.util.asNode(sourceNode).name AS sourceNodeName,
gds.util.asNode(targetNode).name AS targetNodeName,
totalCost,
[nodeId IN nodeIds | gds.util.asNode(nodeId).name] AS nodeNames,
costs,
nodes(path) as path
ORDER BY index
╒═══════╤════════════════╤════════════════╤═══════════╤════════════════════════════╤══════════════╤══════════════════════════════════════════════════════════════════════╕
│"index"│"sourceNodeName"│"targetNodeName"│"totalCost"│"nodeNames" │"costs" │"path" │
╞═══════╪════════════════╪════════════════╪═══════════╪════════════════════════════╪══════════════╪══════════════════════════════════════════════════════════════════════╡
│0 │"Tlemcen" │"Setif" │11.0 │["Tlemcen","Tiaret","Setif"]│[0.0,4.3,11.0]│[{"name":"Tlemcen","latitude":34.8825,"longitude":-1.31393},{"name":"T│
│ │ │ │ │ │ │iaret","latitude":35.3673553,"longitude":1.32203219},{"name":"Setif","│
│ │ │ │ │ │ │latitude":36.18898,"longitude":5.414416}] │
└───────┴────────────────┴────────────────┴───────────┴────────────────────────────┴──────────────┴──────────────────────────────────────────────────────────────────────┘
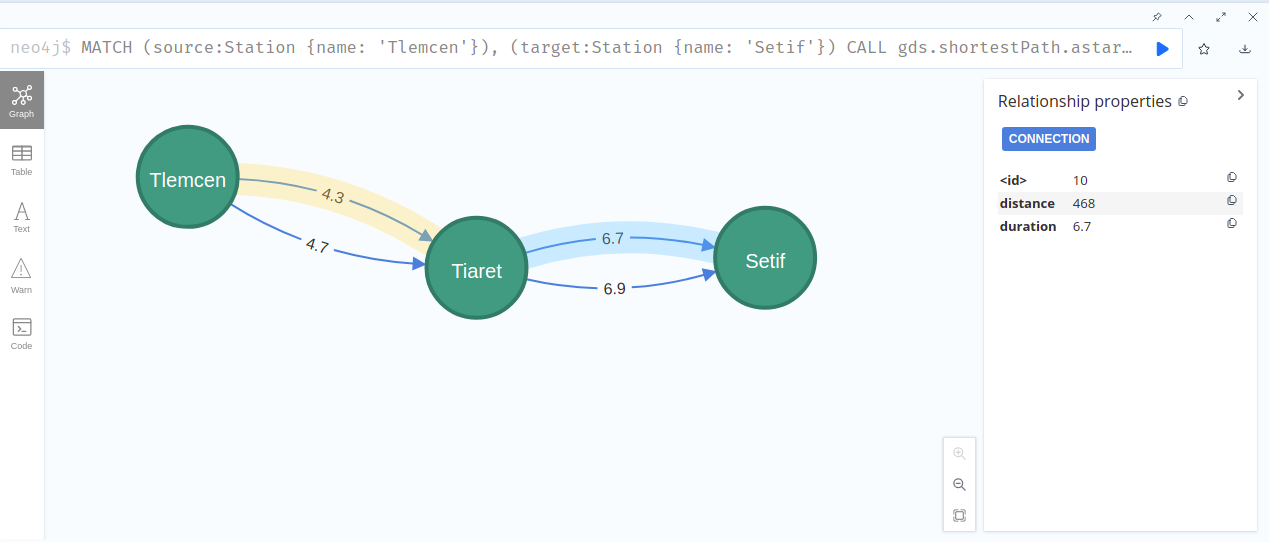

the next cypher query show all the possible connection between them:
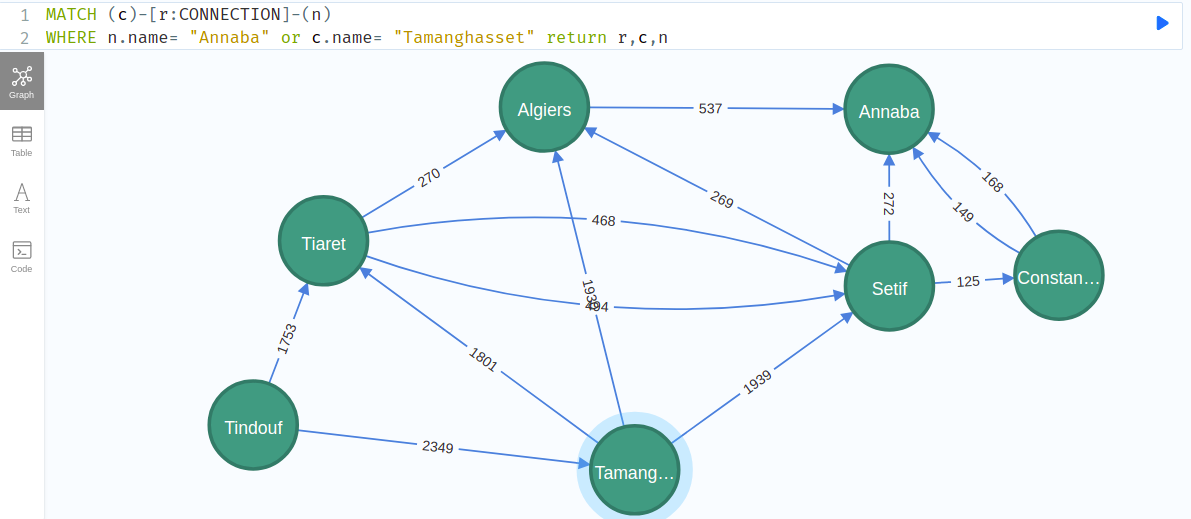
MATCH (c)-[r:CONNECTION]-(n)
WHERE n.name= "Annaba" or c.name= "Tamanghasset" return r,c,n
as you can see, there is multiples path to the same destination:
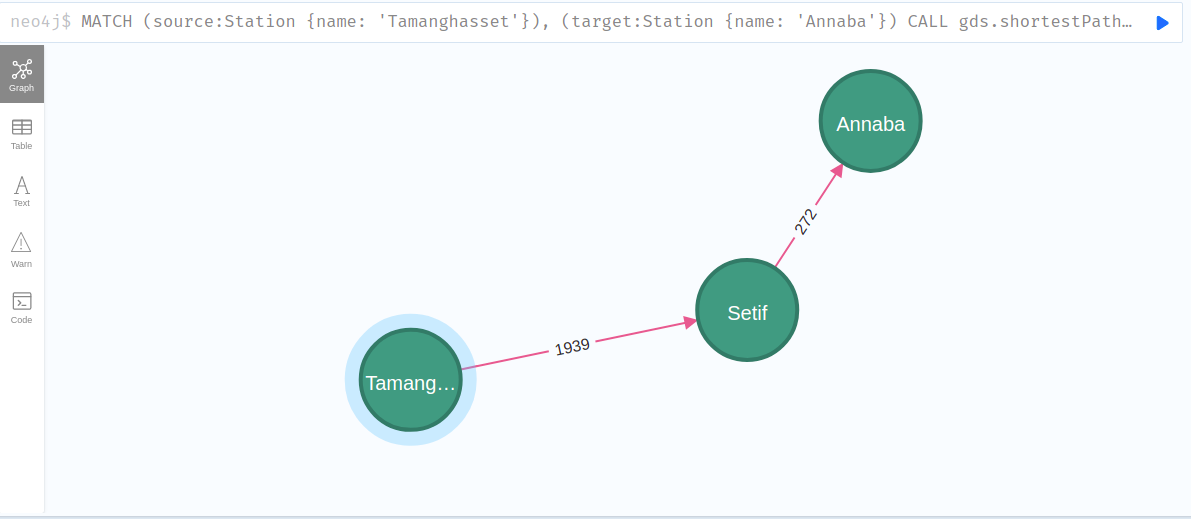
MATCH (source:Station {name: 'Tamanghasset'}), (target:Station {name: 'Annaba'})
CALL gds.shortestPath.astar.stream('AlgeriaGraph', {
sourceNode: source,
targetNode: target,
latitudeProperty: 'latitude',
longitudeProperty: 'longitude',
relationshipWeightProperty: 'distance'
})
YIELD index, sourceNode, targetNode, totalCost, nodeIds, costs, path
RETURN
index,
gds.util.asNode(sourceNode).name AS sourceNodeName,
gds.util.asNode(targetNode).name AS targetNodeName,
totalCost,
[nodeId IN nodeIds | gds.util.asNode(nodeId).name] AS nodeNames,
costs,
nodes(path) as path
ORDER BY index
╒═══════╤════════════════╤════════════════╤═══════════╤═════════════════════════════════╤═══════════════════╤══════════════════════════════════════════════════════════════════════╕
│"index"│"sourceNodeName"│"targetNodeName"│"totalCost"│"nodeNames" │"costs" │"path" │
╞═══════╪════════════════╪════════════════╪═══════════╪═════════════════════════════════╪═══════════════════╪══════════════════════════════════════════════════════════════════════╡
│0 │"Tamanghasset" │"Annaba" │2211.0 │["Tamanghasset","Setif","Annaba"]│[0.0,1939.0,2211.0]│[{"name":"Tamanghasset","latitude":22.7854543,"longitude":5.5324465},{│
│ │ │ │ │ │ │"name":"Setif","latitude":36.18898,"longitude":5.414416},{"name":"Anna│
│ │ │ │ │ │ │ba","latitude":36.902859,"longitude":7.755543}] │
└───────┴────────────────┴────────────────┴───────────┴─────────────────────────────────┴───────────────────┴──────────────────────────────────────────────────────────────────────┘
it should choose the best shortest path for lowest total distance of 2211 km:
Conclusion
now after we come to end of our demo, you have seen how to implement the A* algorithm in Neo4j using real data, and you are able to apply for more advanced algorithms as well.