What is a Data Warehouse?
Publish Date: 2022-01-30 By: Ayadi Tahar
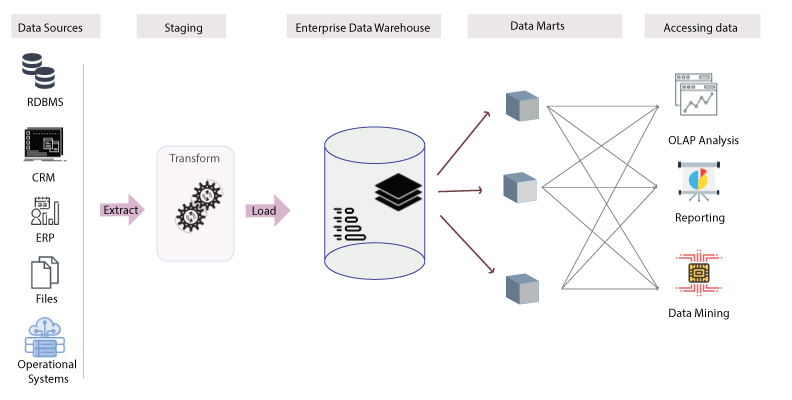
The expansion of big data and the application of new digital technologies are driving change in the way we are looking and using data to respond to different business needs.
Traditional databases are built primarily for fast queries, transaction processing and updating real-time data. Typ
Read moreHow To Install MySQL 8 on Ubuntu 20.04
Publish Date: 2022-06-20 By: Ayadi Tahar

MySQL is a fast, multi-threaded, multi-user, and robust SQL database server. It is intended for mission-critical, heavy-load production systems and mass-deployed software. It is part of database management system provided by Oracle, and can be installed as part of the popular LAMP (Linu
Read moreExternal Vs Managed Tables in Hive
Publish Date: 2022-06-21 By: Ayadi Tahar

If you just start learning Big Data technologies, You might not know that there is 2 main basic types of tables in Apache Hive. Knowing the difference between them and when to use one in place of other, can give you great results and impact your data management. that and more what we
Read moreHDFS Basic Operations
Publish Date: 2022-07-06 By: Ayadi Tahar
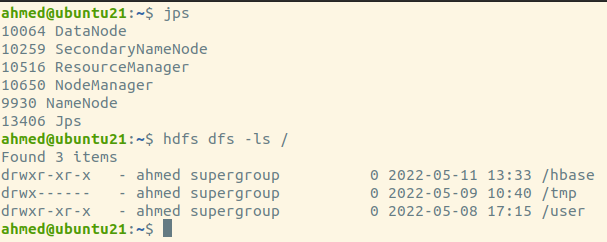
Apache Hadoop project has developed open-source software for reliable, scalable, and efficient distributed computing.
Hadoop Distributed File System (HDFS) is a distributed file system that stores data on low-cost machines, providing
high aggregate bandwidth across the cluster
How to perform broadcast joins in Spark ?
Publish Date: 2022-07-29 By: Ayadi Tahar
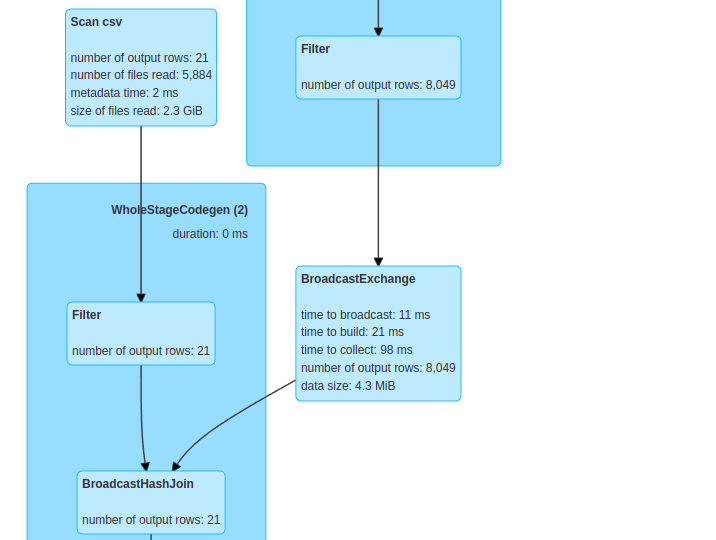
in this article we will see how to perform broadcast join , which known in other names as map side or replicated join, using Apache Spark . If we don’t use a broadcast feature when performing a join on 2 dataframes, it will result in heavy shuffle operations in the cluster, which will
Read more