An Introduction to Graph Data Models
Publish Date: 2022-09-12
If we have to think about our world, society, IT, business, and social communication between peoples, use of machines and interactions with outside world. it is clear that we are in a connected world, and the internet makes all resources tie together.
Our world is full of r...
read moreEssentials Data models in InfluxDB
Publish Date: 2022-09-11

InfluxDB is an open source and popular time series database that was written in Go language, and it's first released in 2013 by Influxdata, to provide a platform optimized for fast, scalable and highly available storage and retrieval of time series data.
As time series data...
read more[draft] Cluster By, Order By, Sort By: When to use each one in Hive
Publish Date: 2022-08-26

...
read moreHow to perform broadcast joins in Spark ?
Publish Date: 2022-07-29
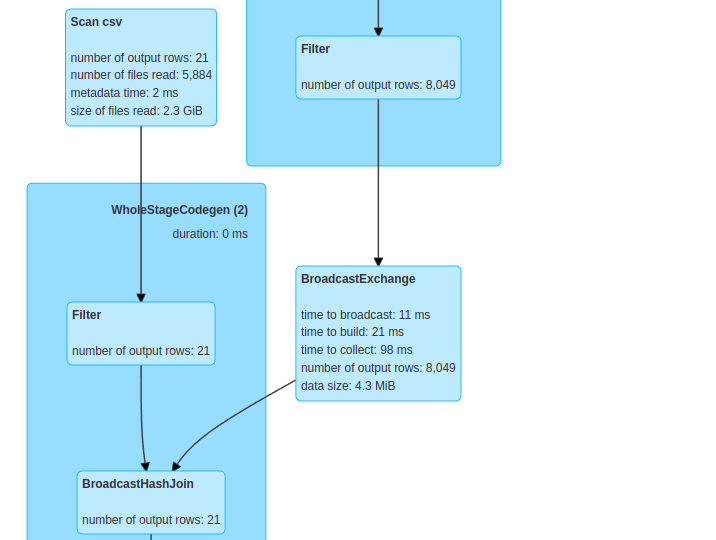
in this article we will see how to perform broadcast join , which known in other names as map side or replicated join, using Apache Spark . If we don’t use a broadcast feature when performing a join on 2 dataframes, it will result in heavy shuffle operations in the cluster, which will...
read moreHDFS Basic Operations
Publish Date: 2022-07-06
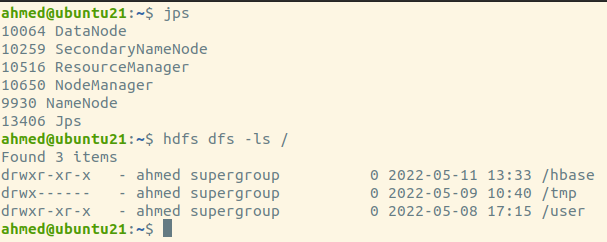
Apache Hadoop project has developed open-source software for reliable, scalable, and efficient distributed computing.
Hadoop Distributed File System (HDFS) is a distributed file system that stores data on low-cost machines, providing
high aggregate bandwidth across the cluster