Master the Basics of Hbase CRUD Operations and Data Manipulations
Publish Date: 2022-09-14 10 min read

In columnar Databases, a table is a collection of rows. but what makes a difference is that the row is a key value pair where the key is the primary identifier for the record. while the value is one or more of column families, which is collection of columns that contain one or more columns or...
read moreColumnar Databases: HBase Data Overview
Publish Date: 2022-09-13 5 min read

Hadoop was initially built for batch jobs in big data, it was not created (at least initially) for reading/writing of large datasets. that because all operations using the Map Reduce I/O framework classes, do the read/write in sequences. Hadoop lacks features for updating single records in large...
read moreAn Introduction to Graph Data Models
Publish Date: 2022-09-12 6 min read
If we have to think about our world, society, IT, business, and social communication between peoples, use of machines and interactions with outside world. it is clear that we are in a connected world, and the internet makes all resources tie together. Our world is full of relationships, and as a...
read moreEssentials Data models in InfluxDB
Publish Date: 2022-09-11 5 min read

InfluxDB is an open source and popular time series database that was written in Go language, and it's first released in 2013 by Influxdata, to provide a platform optimized for fast, scalable and highly available storage and retrieval of time series data. As time series data is different than data...
read moreHow to perform broadcast joins in Spark ?
Publish Date: 2022-07-29 7 min read
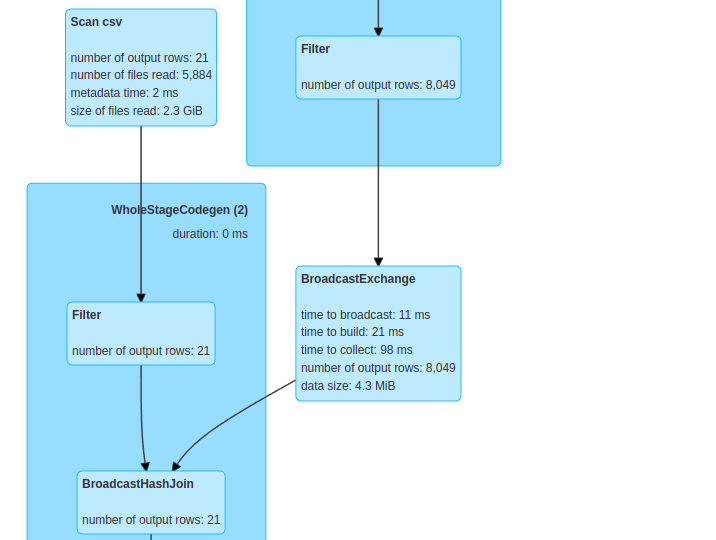
in this article we will see how to perform broadcast join , which known in other names as map side or replicated join, using Apache Spark . If we don’t use a broadcast feature when performing a join on 2 dataframes, it will result in heavy shuffle operations in the cluster, which will make our...
read more